출처: https://news.hada.io/topic?id=9147
Vector Database란?
(pinecone.io)- AI 어플리케이션들은 Vector Embeddings에 의존
- 임베딩은 AI 모델에 의해 생성되며, 많은 수의 속성/피쳐가 있어서 관리하기가 어려움
- AI 및 ML에서 이 피쳐들은 패턴, 관계 및 기본 구조를 이해하는데 필수적인 데이터의 다양한 디멘젼들을 표현
- Pinecone 같은 벡터DB는 이런 임베딩 데이터를 최적화 하여 보관하고 쿼리하기 위해 특화된 DB
- 벡터DB를 통해서 AI에 시맨틱 정보 검색, 장기 메모리 등의 고급 기능들을 구현 가능
- 임베딩 모델을 통해서 인덱싱할 콘텐츠의 벡터 임베딩을 생성
- 벡터 임베딩들을 벡터DB에 삽입. 임베딩이 어디에서 생성되었는지 오리지널 콘텐츠에 대한 레퍼런스를 포함
- 어플리케이션이 쿼리를 하면, 같은 임베딩 모델을 이용하여 쿼리에 대한 임베딩을 생성하고, 이 임베딩으로 DB를 검색해서 비슷한 벡터 임베딩을 찾음
- 이 임베딩들은 오리지널 콘텐츠에 연결되어 있음
Vector Index 와 Vector DB의 차이점
- FAISS(Facebook AI Similarity Search) 같은 벡터 인덱스도 벡터 임베딩 검색을 개선하지만, DB의 기능을 가지고 있지는 않음
- Vector DB는 여러가지 장점을 가짐
- 데이터 관리 기능: 데이터의 삽입, 삭제, 갱신이 쉬움
- 메타데이터 저장 및 필터링: 각 벡터에 대한 메타데이터 저장이 가능
- 확장성: 분산 및 병렬처리 기능을 제공
- 실시간 업데이트 지원
- 백업 및 컬렉션 기능(일부 인덱스만 골라서 백업)
- 에코시스템 연동: ETL(Spark), 분석도구(Tableau, Segment), 시각화(Grafana) 등과 연동. AI 도구와의 연동(LangChain, LlamaIndex, ChatGPT Plugins)
- 데이터 보안 및 접근 권한 관리
Vector DB는 어떻게 동작하는가 ? (소제목만 옮깁니다)
- 알고리듬 : ANN, Random Projection, Product Quantization, Locality-sensitive hashing, Hierarchical Navigable Small World (HSNW)
- 유사성 측정
- 필터링
- 데이터베이스 오퍼레이션
요약
- NLP, 컴퓨터 비전 및 다른 AI 어플리케이션에서 벡터 임베딩이 폭발적으로 성장하면서 벡터 데이터베이스가 등장
- 프로덕션 시나리오에서 벡터 임베딩을 관리할 때 발생하는 문제점을 해결하기 위해 특수하게 만들어진게 벡터 데이터베이스
- 기존의 스칼라 기반 데이터 베이스 및 스탠드얼론 벡터 인덱스에 비해 상당한 이점을 제공
출처: https://hotorch.tistory.com/407
올해 상반기 AI sector에서 핫한 토픽은 AI를 보다 일반인들에게 쉽게, 친숙하게 접근할 수 있는 ChatGPT였습니다. 여기서 같이 수혜주로 받은 것은 Vector Database 분야입니다. 이미 Faiss, Redis, ScaNN 기존 Vector Database 도 있었지만 작년 중순부터 스멀스멀 이야기가 나오던 Pinecone, Chroma, Weaviate, Qdrant 등 새로운 Vector Database가 나타나고 있습니다.
심지어 새롭게 뜨고 있는 Vector Database들에 대해서는 투자 금액이 쏠리고 있습니다. 참고로 Chief AI Officer의 트위터에서 4월 말 기준 투자 금액 기준으로 Top tools를 소개하면 다음과 같습니다.
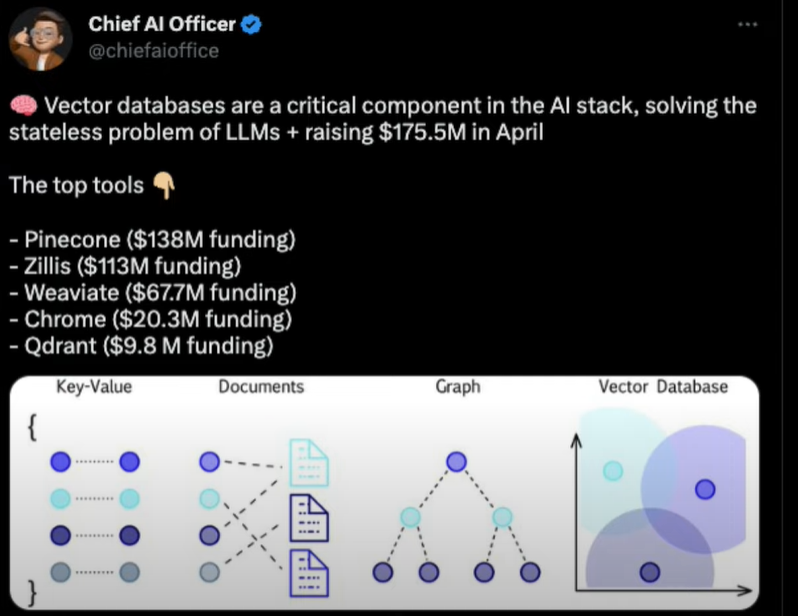
왜 이렇게 갑자기 많은 Vector 관련 Database들이 AI sector에서 화두가 되고 있을까요? 이번 글에서는 그 배경과 필요성을 한번 짚고 넘어가 보고자 합니다.
효율적인 데이터 저장 및 관리, 속도
첫째로 꼽은 것은 비정형데이터를 저장하고 관리하는 것, 그리고 속도의 이점입니다. 이미 전 세계의 데이터가 8~9할 이상이 비정형 데이터인데, 이에 대한 정보를 축약하는 기술인 임베딩한 값들은 기존 Traditional 한 DB. 즉, 관계형 DB 형태로 적재하기 어렵습니다. 하지만 Vector Database는 데이터 관리, 메타데이터 저장 및 필터링을 용이하게 하며 높은 확장성, 백업 및 수집, 실시간 업데이트 등 다양한 방면으로 활용이 가능합니다.
제일 이해하기 쉬운 형태로 여러 Vector DB들 중 chroma db에서 적재되는 형태는 다음과 같이 적재되며 검색하는 형태 예시코드 입니다. (전체 코드는 여기 참고)
# collection에 임베딩값과, 메타정보, 인덱스들이 저장된다.
collection.add(
embeddings=[
[1.1, 2.3, 3.2],
[4.5, 6.9, 4.4],
[1.1, 2.3, 3.2],
[4.5, 6.9, 4.4],
[1.1, 2.3, 3.2],
[4.5, 6.9, 4.4],
[1.1, 2.3, 3.2],
[4.5, 6.9, 4.4],
],
metadatas=[
{"uri": "img1.png", "style": "style1"},
{"uri": "img2.png", "style": "style2"},
{"uri": "img3.png", "style": "style1"},
{"uri": "img4.png", "style": "style1"},
{"uri": "img5.png", "style": "style1"},
{"uri": "img6.png", "style": "style1"},
{"uri": "img7.png", "style": "style1"},
{"uri": "img8.png", "style": "style1"},
],
documents=["doc1", "doc2", "doc3", "doc4", "doc5", "doc6", "doc7", "doc8"],
ids=["id1", "id2", "id3", "id4", "id5", "id6", "id7", "id8"],
)
# vectordb 내부에서 inference할 임베딩값과 유사한 top n의 값을 정하면 결과를 얻을 수 있다.
query_result = collection.query(
query_embeddings=[[1.1, 2.3, 3.2], [5.1, 4.3, 2.2]],
n_results=2,
)
print(query_result)
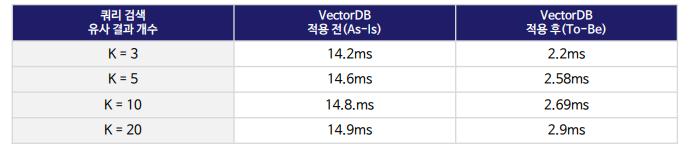
개인적으로 속도 부분이 제일 궁금하여, 자체적으로 실험을 했을 때 내용을 공유하면 다음과 같습니다. 설치가 제일 쉬운 Chroma를 기준으로 선정하였습니다.
- vector DB를 쓰는 경우는 Chroma DB를 활용(To-Be 방법)하고, 쓰지 않는 경우(As-Is 방법)는 그냥 python 자체에서 활용한다.
- 15만 개의 텍스트를 따로 준비하고 huggingface에서 특정 sts 모델(snunlp/KR-SBERT-V40K-klueNLI-augSTS)을 활용하여 sbert를 적용한다.
- 2번에서 뽑혀 나온 768차원 임베딩 벡터들을 Chroma DB에 add 시킨다. 그리고 위 코드와 같이 collection.query() 를 활용하여 시간을 측정한다.(To-Be)
- python 자체에서 활용하는 방법은 sbert의 공식 document에서 제시하는 Semantic Search 코드와 유사하게 검색한다. (As-Is)
시간 측정은 동일한 코드를 10,000번 수행하여 소요된 시간의 표본 평균입니다. 결과는 7배 정도 차이가 났습니다.
Large Language Model과의 결합
두 번째 필요성은 LLM과의 결합했을 때입니다. Static 한 Large Language Model(LLM)에 대한 단점은 무거움이나 재학습, 서빙 등 다양한 허들 요소들이 있겠지만 일반인들도 ChatGPT를 좀 써봤다고 생각했을 때 경험해 본 '환각(hallucination)' 현상입니다. 일반인들에게 '환각' 현상이 뭐예요?라고 물어본다면, LLM이 자존심이 너무 세서 모르는 것에 모른다고 답하지 않고, 그럴싸하게 자연어를 생성해서 대답한다고 예를 드시면 됩니다.

또한 ChatGPT API를 써보신 분들은 다양한 Parameter들을 마주하게 되는데, 이때 답변의 랜덤성을 담당하는 temperature 값을 0으로 설정하여 LLM이 동일한 응답을 제공하려고 합니다. 하지만 이 부분은 일관성과 관련된 부분을 관장하고 담당하지만 답변의 결과는 신뢰도까지 직결되지 않습니다.
그래서 이를 해결하기 위해서 임베딩 모델 한 번만 태우고, 이를 적재하고 빠르게 읽어오기 위해 Vector Database를 활용합니다. (아래 그림을 langchain과 Vector Database를 결합한 예시입니다)
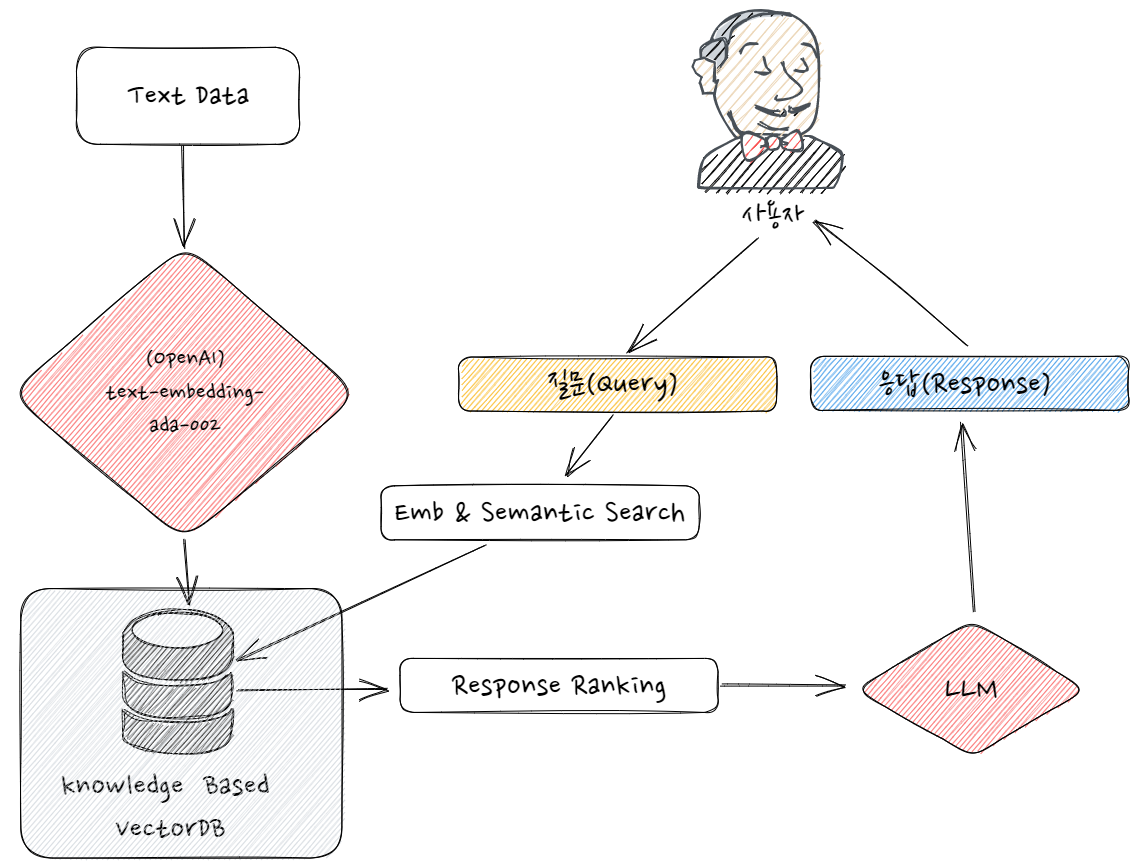
이를 통해 knowledge에 적재된 Vector Database 부분만을 참고하여 원하는 범주 내에서 질의응답이나 활용을 할 수 있습니다. 이런 방법을 이용하면 환각에 대한 부분을 어느 정도 막을 수 있습니다. 여기서 프롬프트를 고정하고 내가 어떤 Vector Database를 쓰느냐에 따라서 시간 차이가 엄청나게 납니다. (이 부분은 또 다른 콘텐츠에 작성해 보겠습니다)
다양한 분야 & 세부 Task에서 활용
마지막 필요성은 이미 많은 분야에서 사용이 되고 있다는 점입니다. 우선 모델에서 만든 임베딩한 고차원의 vector (dense하든 sparse하든 이 부분은 무관합니다) 들은 이미 많은 세부 task에서 활용되고 있다는 점입니다. 사용분야의 예시로는 semantic search, QA, 이상탐지, image 검색, 추천시스템 등에 적용을 하고 있습니다.
실제로 이를 product 단에서 사용하고 이를 공유하는 국내 글은 아직까지는 많이 없는 것 같습니다. 아래 글은 추천시스템에서 실제로 활용하고 있는 글입니다. 한번 참고해 보시면 좋겠습니다.
Reference :
- 컨텐츠 기반 필터링 구축기: MiniLM, ScaNN 그리고 TFServing
- 그 많던 벡터는 다 어디로 갔을까? Milvus 활용기
이번 글에서는 Vector Database에 대한 필요성을 점검해 보았습니다. Claypot AI의 Chip Huyen(Stanford, NVIDIA 출신)의 "Building LLM applications for production" 의 글에서 이 분이 다음과 같은 표현을 했습니다.
"If 2021 was the year of graph databases, 2023 is the year of vector databases."
저는 이런 확신에 차는 한마디는 무조건 한번은 경계를 하는 편인데, 저는 이 확신을 뼈저리게 느끼고 있기 때문에 매우 공감합니다. 다음 글에는 Vector Database에서 어떤 종류들이 있고 간단하게 비교해 보겠습니다.
2023.07.24 - [AI/Vector Database] - [Vector DB] 2. Vector Database 종류 & 한계점
[Vector DB] 2. Vector Database 종류 & 한계점
이전 글에서는 Vector DB가 떠오르고 있는 배경과 왜 필요한지에 대해 글을 작성하였습니다. 2023.06.10 - [AI/Vector Database] - [Vector DB] 1. Vector Database 배경 & 필요성 [Vector DB] 1. Vector Database 배경 & 필요성
hotorch.tistory.com
Milvus 관련 글
2023.10.10 - [AI/Vector Database] - [Vector DB] 3. Milvus 튜토리얼 (1) - 설치, 변수 정의, Collection 생성하기
2023.10.12 - [AI/Vector Database] - [Vector DB] 4. Milvus 튜토리얼 (2) - Collection에 데이터 insert 하기
2023.10.13 - [AI/Vector Database] - [Vector DB] 5. Milvus 튜토리얼 (3) - Query 임베딩 생성 & Vector DB 검색하기
2023.10.19 - [AI/Vector Database] - [Vector DB] 6. Milvus 튜토리얼 (4) - Collection에 데이터 Upsert 하기
'프로그램 활용 > 인공지능(AI)' 카테고리의 다른 글
| AI 코드 생성기 (0) | 2024.01.17 |
|---|---|
| 상업적 이용가능한 LLM 프로젝트들 5가지 (0) | 2024.01.13 |
| [AI][기고] Stable Diffusion: 델파이로 내 PC에서 구현되는 생성형 AI (0) | 2023.09.05 |
| Ubuntu 20.04 + Docker 20.04 + Kubernetes 1.23.6 +Django 4.0.3 + React 18.0 +MySql 8.0.28 +Machine Learning : pytorch 1.11.0 cuda 10.2 (0) | 2023.08.03 |
| ChatGPT4 (챗GPT4, 챗지피티4) 무료 사용방법 (0) | 2023.04.05 |


