6. Redo & Archived Logs
지난 Database Architecture (DISK) 강의에서는 데이터베이스 유지에 필수 파일인
Control File, Datafile, Redo Log File에 대해서 설명 드린 바 있습니다.
이번 시간에는 필수 파일 중 하나인 Redo Log에 대하여 자세히 설명 드리도록 하겠습니다.
기본적으로 Redo Log는 데이터의 변경 내역을 저장하는 파일입니다.
따라서 Buffer Cache에 올라 와있는 데이터 블록과 디스크 데이터 블록이 동기화가 필요할 때
이 Redo Log를 기록한 후 DBWR(DB 라이터)가 데이터를 변경시킵니다.
한 가지 중요하게 짚고 넘어가야 할 것은,
Redo data가 Online Redo Log File에 기록되기 전까지
DBWR은 절대 데이터를 변경하지 않는다는 것입니다.
조금 더 확장해서 생각하면 Redo Log가 완전히 기록되기 전까지는
DBWR은 대기 상태라고 말씀드릴 수 있습니다.
실생활에서 출석 체크를 할 때를 예로 들어 설명 드리겠습니다.
사무실에 출근해서 출석 체크하는 방식으로는
홍채 인식 기계를 통해 체크를 하는 방식과
메모장에 이름을 적는 방식으로 체크를 한다고 예를 들어봅시다.
홍체 인식을 통해 출석 체크를 하면 약 30초 가량 소요되고,
메모장 출석 체크를 하면 약 3초가 소요된다고 가정할게요.
홍채 인식 기계는 직접 생체 정보가 저장되어 있는 데이터베이스에 접근하여
생체 정보를 비교하고 출석체크를 하기 때문에 속도가 많이 느립니다.
따라서 출퇴근이 몰리는 08시 50분과 18시 10분쯤 되면
출석 체크를 위한 대기 열이 생길 것입니다.
하지만 만약 홍채 인식 기계를 이용하지 않고
철수라는 관리자가 사무실 문을 통과하는 사람들의 이름을
메모장에 적어 놨다가 나중에 시간적 여유가 있을 때
전산 상에 출석 정보를 하나씩 입력한다고 하면,
출석 체크를 위한 대기 열은 생기지 않을 것입니다.
여기서 만약 관리자 철수가 메모장을 잃어버리거나,
메모장에 이름을 쓰기도 전에 사람들이 통과해버리면
누가 출석을 했고 누가 결근을 했는지 모르기 때문에
데이터의 정합성에 문제가 생길 것입니다.
그래서 메모장에 이름이 적히지 않으면
사무실 문으로 들어갈 수 없도록 하는 규칙이 필요할 것입니다.
여기서 메모장 역할을 하는 것이 Redo Log,
메모장에 기록을 하는 관리자 철수는 로그라이터(LGWR)에 빗대어 생각할 수 있습니다.
즉, 메모장에 이름이 적히지 않으면 사무실로 들어갈 수 없는 예시처럼
온라인 리두 로그 파일에 리두 로그(데이터 변경내역)가 완전히 쓰일 때까지
데이터 파일에 변경 사항을 적용하는 체크포인트는 대기하게 됩니다.
Redo Log는 데이터가 변경된 내역을 전부 저장했다가
나중에 데이터를 내려쓰거나 데이터를 복구할 때 쓰이는 파일입니다.
따라서 Redo Log 역시 데이터베이스 운영에 핵심이 되는 파일이므로 다중화하여 기록할 수 있습니다. Redo Log의 다중화는 최소 2개의 그룹으로 이루어지며
각 그룹마다 최소 1개의 Redo Log 파일이 존재해야합니다.
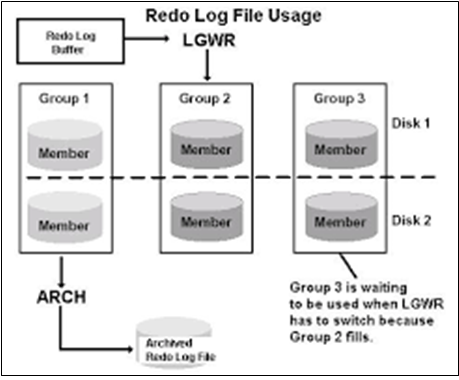

한 그룹의 Redo Log를 다 쓰고 다음 그룹으로 넘어가는 현상을 Log Switch라고 하고,
반복된 로그 스위치를 거치며 마지막 그룹에서 최초의 그룹으로 돌아와서(한바퀴 돌고)
첫번째 리두 데이터를 덮어쓰기 시작하는 것을 Log Spinning이라고 합니다.
통상적으로 Log Switch와 Log Spinning이 발생할 때 Checkpoint가 발생하여
동기화가 필요한 Dirty Buffer들을 디스크의 데이터 파일에 내려씁니다.
Checkpoint가 끝나지 않은 상태에서 다음번 Log Switch나 Log Spinning이 발생할 경우가 되면
Oracle은 Checkpoint가 끝날 때까지 이후 Transaction들을 대기하게 합니다.
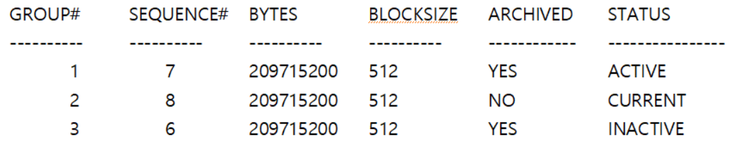
Redo Log에 대한 정보는 V$LOG, V$LOGFILE이라는
Dynamic Performance View를 통해 조회할 수 있습니다.
위 View의 Status라는 컬럼에 대해 조금 더 자세히 설명 드리자면,
1. CURRENT는 현재 Redo Log가 작성 중인 로그파일(Checkpoint가 아직 수행되지 않음),
2. ACTIVE는 Checkpoint를 통해 메모리와 디스크 내 데이터 파일 간
동기화가 아직 끝나지 않은 Redo Log 파일,
3. INACTIVE는 Checkpoint를 통해 메모리와 디스크 간 동기화가 끝나서
다음 시퀀스의 Redo Log를 덮어 쓸 준비가 되어있는 상태의 Redo 파일을 의미합니다.
Redo Log File의 상태는 장애 조치를 할 때 매우 중요하게 작용합니다.
이미 Checkpoint가 끝난 INACTIVE 상태의 Redo Log 분실 시에는
Redo Log Group을 새로 만들어준 후 전체 백업을 수행하는 것으로
비교적 쉽게 장애 조치가 끝나지만,
Checkpoint가 끝나지 않은 ACTIVE나 CURRENT 상태의 Redo Log File이 분실되었다면
Redo Log Clear 작업이나 전체 백업 Restore/Recover 작업이 필요하기 때문에
Down Time이 길고 복구 난이도도 높습니다.
따라서, Redo Log의 상태에 대해 정확히 이해하고
문제가 되는 Redo Log File의 상태에 따라
적절한 방법으로 백업 복구를 수행할 수 있어야합니다.
이에 대한 자세한 내용과 실습은 백업&복구 강의에서 다루도록 하겠습니다.
Archived Logs
다음은 Archive Log에 대해 설명 드리겠습니다.
앞서 말씀드린 것과 같이 Redo Log의 작성이 끝나면
다음 그룹의 온라인 Redo Log 파일에 리두 로그를 기록하기 시작하고,
기존에 쓰여 있었던 리두 내용을 덮어쓰게 됩니다. (로그 스위치)
하지만 Redo Log가 중간에 하나라도 빠지게 되면
백업 파일이 있더라도 완전 복구가 불가능합니다.
따라서 Redo Log File의 내용이 덮어쓰기 전에 백업을 받아야 하는데
이것이 Archived Redo Log입니다.
Archive Log는 Redo Log를 복사한 것이기 때문에
Redo Log의 내용을 고스란히 가지고 있습니다.
(이 개념은 추후에 백업&복구 때 중요하게 쓰입니다.
복구 시에는 Redo = Archived Logs 라고 생각하시면 편할 것 같네요.)
다시 ‘조선왕조실록’ 이야기로 돌아가서 예를 들어보겠습니다.
당시 조선에서는 ‘사관’이 있었던 열심히 일을 받아쓰고 ‘춘추관’에 작성된 실록을 보관했다고 합니다.
또한, 완성된 실록을 복사하여 춘추관, 충주, 전주, 성주의 4 사고에 1부씩 보관했다고 합니다.
여기서 각 사고에 소산하여 보관한 ‘조선왕조실록’을 Archived Redo Log라고 생각하면
이해에 도움이 될 것이라 생각합니다.
즉, LGWR(로그라이터)라는 ‘사관’이 Redo Log를 작성하고,
작성된 Redo Log라는 ‘조선왕조실록’을 사고(백업장치)에 저장한다고 생각하면 좋을 것 같네요.
(참고로 Archived Redo Log는 최대 32개까지 동시에 생성하여 각기 다른 장소에 보관할 수 있습니다.)
출처: https://m.blog.naver.com/xogstar/221764039673
'법, 용어 > 용어' 카테고리의 다른 글
| unmount eject 차이 (0) | 2024.06.15 |
|---|---|
| OpenstackOpenstack Cinder/Swift란? (block storage/object storage) (0) | 2024.06.10 |
| redo log 란 (0) | 2024.06.08 |
| WebRTC란? (1) | 2024.06.03 |
| 통합 테스트 (0) | 2024.05.28 |


