Before we dive into this topic, let us talk about RAG and vector databases.
What is RAG?
Retrieval Augmented Generation, or RAG is a technique to enhance search experience by incorporating LLMs. Instead of searching for an answer by going through an entire document, you can ask your chat assistant to fetch the relevant answers from the document in an easy-to-understand language.
How does it work?
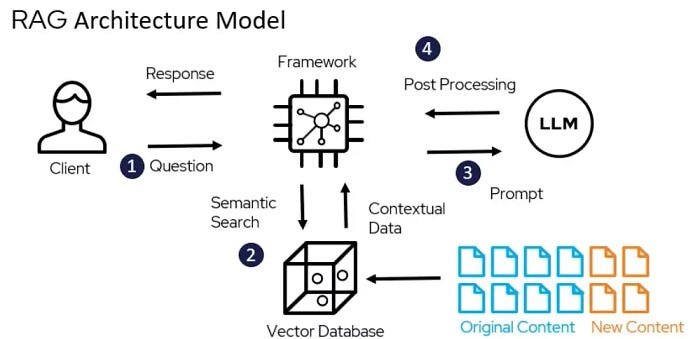
https://medium.com/@bijit211987/advanced-rag-for-llms-slms-5bcc6fbba411
- The data outside the LLM’s original training data is called the external data. This data is converted into numerical representations and stored in a vector database. This process creates a knowledge library that the generative AI models can understand.
- Then the user’s query is converted to a vector representation and matched with the vector databases.
- Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context. This step uses prompt engineering techniques to communicate effectively with the LLM. The augmented prompt allows the large language models to generate an accurate answer to user queries.
What is Verba?
Verba is an open source tool that gives a user-friendly interface for RAG that can be configured locally with Ollama or HuggingFace, or with LLM providers such as OpenAI, Cohere, and Google.
How to install Verba?
Before installing verba, you need to set up a virtual environment in Python. Make sure you have Python version 3.10.0 or above.
To set up virtual environment, install virtualenv package:
pip install virtualenvCreate a virtual environment:
python3 -m virtualenv venvActivate the virtual environment:
For Windows:
venv\Scripts\activate.batFor MacOS or Linux:
source venv/bin/activate(Note: Make sure to deactivate virtual environment after all your work is done with Verba by typing ‘deactivate’.)
Install Verba:
pip install goldenverbaTo configure Ollama as a generator, create a .env file in the same location where you are going to start Verba, with the following content:
OLLAMA_URL =URL to your Ollama instance (e.g. http://localhost:11434 )
OLLAMA_MODEL=Model Name (e.g. llama3)
Check my previous post on how to setup and use Ollama.

Now you can launch Verba with the following command:
verba startAccess http://localhost:8000 once Verba starts.
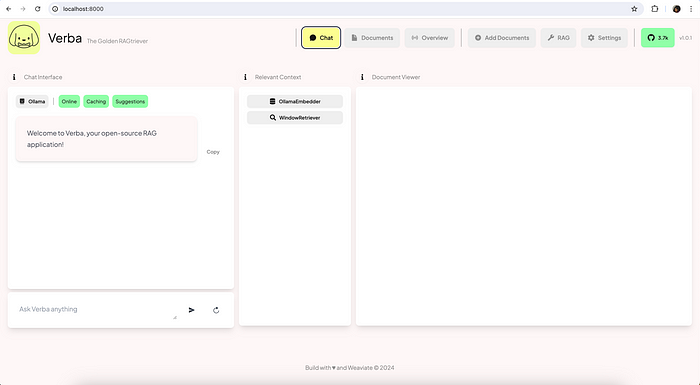
Check the ‘Overview’ and you’ll find Ollama URL and model configured:
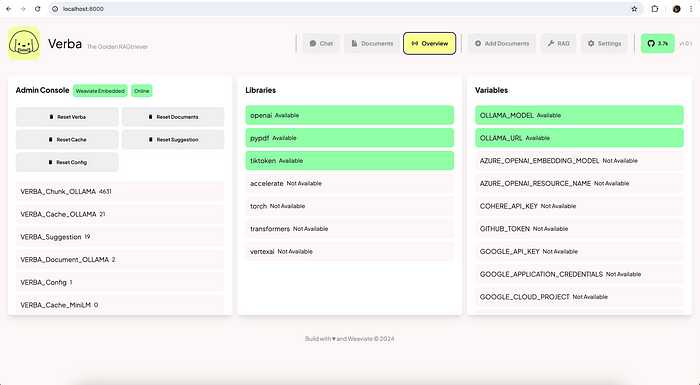
Go to ‘Add Documents’ and you can upload your documents and import them. Verba will create chunks from the data in your document, vectorize those chunks and save it in the vector database.
Click on ‘Add Files’, upload your file and click on ‘Import’.
Once imported, the file will be available in the documents section:
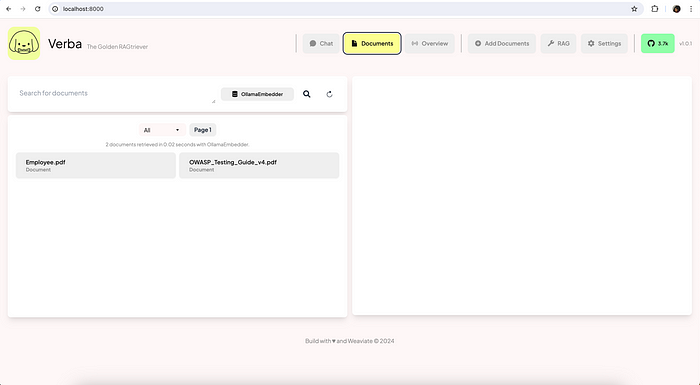
Ask questions and Verba will give you context-based answers.
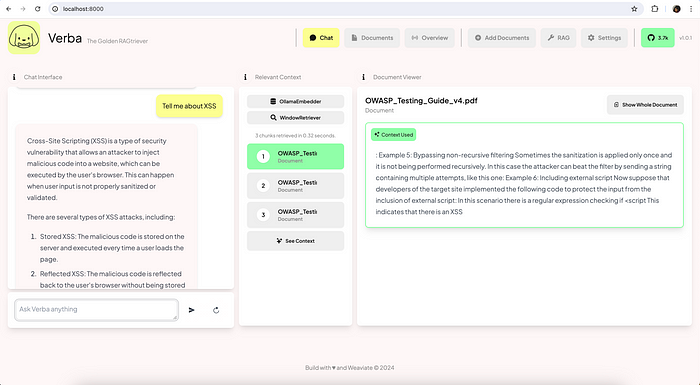
Here are some ways you can use RAG as a penetration tester:
- Documentation: Collect documentation of common software, libraries, and tools used in your target environments.
- Vulnerability Databases: Include databases like CVE, NVD, Exploit-DB.
- Internal Knowledge Base: Gather previous penetration test reports, internal documentation, and known issues within your organization.
- Security Forums and Blogs: Scrape or download relevant data from forums like Stack Overflow, security blogs, and other resources.
- Reconnaissance: Use the RAG system to gather information about the target. For instance, you can query for known vulnerabilities of specific software versions identified in the target environment.
- Exploitation Techniques: Retrieve detailed exploitation techniques or scripts from your corpus based on the identified vulnerabilities.
- Best Practices: Ask for best practices or remediation steps for identified vulnerabilities, leveraging up-to-date security guidelines.
The best part is: using RAG with your local LLMs gives you complete data privacy. Your data is not going outside. You can run your LLM without internet!
'프로그램 활용 > 인공지능(AI)' 카테고리의 다른 글
| OLLAMA + LLAMA3 + RAG + Vector Database (Local, Open Source, Free) (1) | 2024.12.05 |
|---|---|
| AI LLM RAG 구성 (0) | 2024.12.05 |
| Ollama와 LangChain으로 RAG 구현하기 (with Python) (2) | 2024.12.05 |
| LLaMA3 을 이용한 RAG 구축 + Ollama 사용법 정리 (1) | 2024.12.05 |
| AI Ollama 설치와 운영 : 로컬 환경에서 대규모 언어 모델을 쉽게 실행하기 (0) | 2024.12.05 |



