☕ 개요
java -Xms2048m -Xmx2048m -jar application.jarJava로 개발한 프로그램을 실행할 때, Heap메모리의 사이즈를 지정하기 위해서 위와 같은 형태로 프로그램을 실행하곤 한다. 이는 JVM이 사용할 Heap메모리의 사이즈를 지정하는 옵션인데, 이번 글에서는 적절한 Heap메모리 설정에 대한 이야기를 해보도록 하겠다.
📒 Xms, Xmx의 의미
먼저, Xms와 Xmx이 어떤 의미를 갖고 있는지 알 필요가 있어서, 이들에 대해서 간단히 정리해보자.
- Xms : 이 매개변수는 Heap메모리의 초기 사이즈를 의미한다.
- Xmx : 이 매개변수는 Heap메모리의 최대 사이즈를 의미한다.
🤔 Heap메모리를 잘!설정해야하는 이유 : GC
1) GC
JVM에서 GC는 주기적으로 메모리 내에 사용되지 않는 데이터들을 제거해주는 역할을 한다. 그런데, GC가 동작할 때는 다른 쓰레드는 멈추고, GC의 쓰레드만 동작하게 된다. 즉, 비지니스 로직들이 수행되어야하는 쓰레드들이 멈추게 되는 것이다(a.k.a Stop the world).
즉, 최대 Heap메모리 사이즈가 작게 설정이 되어 있으면, GC가 그만큼 자주 발생할 것이고 이는 성능적으로 문제가 될 수 있어서 가능하면 넉넉하게 Heap메모리를 설정해줘야한다.
2) 초기 Heap메모리와 최대 Heap메모리 사이즈
Heap메모리가 부족하면, 최대 Heap메모리 사이즈가 될때까지 추가적으로 메모리 사이즈를 할당한다.
예를 들어서 초기 Heap사이즈를 1G 최대 Heap사이즈를 4G로 설정했다고 해보자. 서비스가 구동되면서, 1G가 넘는 데이터가 Heap메모리에 할당이 된다면, 필요한만큼 Heap메모리 크기를 늘리게 될 것이다. 이 과정 자체는 정상적인 것이지만, 문제는 이 과정이 일어나면 GC가 동작하는 것이다.
즉, 추가 Heap을 요청하는 행위가 빈번하게 발생할 수록 GC도 빈번하게 발생하는 것이다.
🤓 Best practice
Heap메모리를 설정하는 것에는 물론 정답은 없다. 하지만, 일반적인 관점에서 '이렇게 하는 게 좋다'라고 할 수 있는 부분들이 있다.
1) Xms와 Xmx를 동일하게
java -Xms1024m -Xmx2048m -jar application.jar // ❌java -Xms2048m -Xmx2048m -jar application.jar // 👍위에서도 설명했듯이, Heap메모리 추가 요청은 최대한 발생하지 않도록 하는 것이 좋다. 초기 Heap메모리 사이즈를 최대 Heap메모리 사이즈와 동일하게 설정하면, Heap메모리 추가 요청이 발생하는 상황을 회피할 수 있어서, 최초값과 최대값을 동일하게 설정하는 것이 권장된다.
2) 비율로 메모리 사이즈 설정하기
서버의 스펙이 모든 상황에서 동일하다면, 굳이 비율(Percentage)로 메모리 사이즈를 설정해줄 필요는 없겠지만, 실제로는 매우 다양한 서버에서 동일한 서버 애플리케이션이 구동되곤 한다. 그래서 구동되는 서버마다 메모리 사이즈를 설정하는 것을 피하고, 어떤 서버에서나 동일한 수준의 메모리를 할당하고 싶다면, Heap메모리 사이즈를 비율로 설정하면 된다.
- -XX:InitialRAMPercentage (-Xms 옵션이 설정되어 있으면 이 옵션은 무시)이 옵션은 초기 Heap메모리 사이즈를 물리 메모리에 대한 비율로 설정하는 옵션이다. 위와 같이 설정하면, 서버 메모리의 50%가 초기 Heap메모리로 할당되게 된다.
- java -XX:InitialRAMPercentage=50.0 -jar application.jar
- -XX:MinRAMPercentage (-Xmx 옵션이 설정되어 있으면 이 옵션은 무시)이 옵션은 이름에서 유추되는 것과 달리 최대 메모리 사이즈를 지정하는 옵션이다. 다만, 서버가 256MB미만의 메모리를 갖고 있을 때만 이 옵션은 동작한다.
- java -XX:MinRAMPercentage=50.0 -jar application.jar
- -XX:MaxRAMPercentage (-Xmx 옵션이 설정되어 있으면 이 옵션은 무시)이 옵션도 위와 마찬가지로 최대 Heap메모리 사이즈를 지정하는 옵션이다. 서버가 256MB이상의 메모리를 갖고 있는 경우 이 옵션은 동작한다.
- java -XX:MaxRAMPercentage=50.0 -jar application.jar
🙏 참고
- JVM 의 Xmx 와 Xms 를 지정해야 하는 이유에 대해
- Baeldung - JVM Parameters
- [JVM 매개변수] InitialRAMPercentage, MinRAMPercentage, MaxRAMPercentage
출처: Java Heap Memory Size 확인 및 설정하기 : 네이버 블로그
Java Heap Memory Size 설정하기
1. 현재 시스템의 메모리 설정값 확인
초기/최대 힙 메모리가 이렇게 계산이 된댄다.
Heap sizes
Initial heap size of 1/64 of physical memory up to 1Gbyte
Maximum heap size of 1/4 of physical memory up to 1Gbyte
* 항상 이렇게 되지는 않는다고 한다(Ergonimics - 요즘으로 치면 A.I. 쯤 되려나)
참고: Ergonomics
메모리 구조
출처: https://st-lab.tistory.com/198
안녕하세요.
오늘은 제목에서 밝혔듯 메모리 구조에 대해 알아보려 합니다. 흔히 메모리라고 하면 RAM을 지칭하는데요, 보통 컴퓨터 구조에 대해 학습하시거나 배우셨던 분들은 알겠지만 메모리의 종류는 많아도 엄청 많은 걸 알고 있을 겁니다. 그만큼 컴퓨터에서는 매우 중요한 부품 중 하나죠. 컴퓨터 구조에 대해 전반적으로 다루려고 하면 내용이 너무 많아지기 때문에 오늘은 메모리에 대해 우리가 코딩한 것과 어떤 관계가 있는지를 알아보고자 합니다.
왜 그러면 다른 것들도 많은데 메모리냐! CPU나 명령어 셋이 더 중요하지 않냐! 라고 하실 수도 있겠지만, 틀린 말은 아니더라도 메모리도 매우 중요하다고 봅니다.
특히 알고리즘 문제를 많이 풀어본 분들은 알겠지만, 한정된 자원 안에서 효율적으로 프로그램이 실행 될 수 있도록 하기 위해서는 기본적으로 메모리에 대한 이해를 필요로 하기 때문이죠.
오늘은 C언어가 조금 많이 보일 수도 있지만, 아예 모르더라도 최대한 설명을 해서 알려주고, 최소한만 알아도 이해할 수 있도록 노력해서 써보겠습니다.
그럼 한 번 하나씩 알아보도록 하죠.
- 메모리 구조 (Memory Structure)
여러분들은 C언어, C++, Java 등의 언어들을 이용하여 코딩을 하고 실행파일로 만들겁니다. 예로들면 C언어로 작성하여 빌드하고 만든 실행파일인 .exe 파일처럼 말이죠.
이러한 실행파일을 실행시키면 메모리에 로드되면서 코드에서 작성한 동작에 따라 메모리에 데이터들을 쓰고 읽습니다.
좀 더 구체적으로 말하자면, 여러분이 실행파일을 만들어 실행파일로 디스크에 저장할겁니다. 그리고 사용자가 실행파일을 더블클릭(실행)할테죠. 이를 운영체제에 실행파일을 실행하도록 요청하는 것입니다. 그러면 운영체제는 프로그램의 정보들을 읽고 메인 메모리에 공간을 할당해줍니다. 그리고 프로그램의 코드(변수, 함수 등)들을 메모리에 읽고 쓰면서 동작을 하게 되죠.
하지만, 일단 설명에 앞서 유의할 점은 임베디드 환경과 우리가 일반적으로 사용하는 PC컴퓨터(x86, x64 등등)에서의 환경하고는 조금 차이가 있습니다. 여기서는 모든 예시가 일반적인 환경(OS)에서 사용한다는 가정하에 설명드리겠습니다.
그럼 메모리에 어떻게 올라가는지를 알아보기 전에 메모리의 구조를 대략적으로나마 보겠습니다.

각 언어마다 조금씩 차이가 있지만 전체적인 구조 자체는 위 사진과 같이 영역이 나뉩니다. 보다시피 4가지의 영역으로 구분되죠.
일단, 각 영역별로 간단하게 설명하도록 하겠습니다.
[Text]
텍스트 영역은 아주 쉽게 말하면 코드를 실행하기 위해 저장되어있는 영역입니다. 흔히 코드 영역이라고도 하는데, 프로그램을 실행시키기 위해 구성되는 것들이 저장되는 영역입니다. 한마디로 명령문들이 저장되는 것인데, 제어문, 함수, 상수들이 이 영역에 저장됩니다.
[Data]
데이터 영역은 우리가 작성한 코드에서 전역변수, 정적변수 등이 저장되는 공간입니다. 이들의 특징을 보면 보통 메인(main)함수 전(프로그램 실행 전)에 선언되어 프로그램이 끝날 때 까지 메모리에 남아있는 변수들이라는 특징이 있습니다.
좀 더 구체적으로 말하자면 Data영역도 크게 두 가지로 나뉩니다.
초기화 된 변수 영역(initialized data segment)과 초기화되지 않은 변수 영역(uninitialized data segment)으로 나뉘죠. 그리고 그 중 초기화되지 않은 변수 영역은 BSS(Block Started by Symbol) 이라고도 합니다.
[Heap]
힙 영역은 쉽게 말해서 '사용자에 의해 관리되는 영역'입니다. 흔히 동적으로 할당 할 변수들이 여기에 저장된다고 보시면 됩니다. 또한 Java나 C++에서 new 연산자로 생성하는 경우 또는 class, 참조 변수들도 Heap영역에 차지하게 됩니다. 다만, 이는 언어마다 조금씩 상이하니 일단은 '동적 할당 영역'이라고 알아두시면 될 것 같습니다.
그리고 Heap 영역은 대개 '낮은 주소에서 높은 주소로 할당(적재)됩니다'
[Stack]
스택 영역은 함수를 호출 할 때 지역변수, 매개변수들이 저장되는 공간입니다. 메인(main) 함수안에서의 변수들도 당연 이에 포함되죠. 그리고 함수가 종료되면 해당 함수에 할당된 변수들을 메모리에서 해제시킵니다. 한마디로 Stack 자료구조의 pop과 같은 기능이죠.
여러분이 함수를 '재귀' 호출 할 때, 재귀가 깊어져 Stack Overflow 를 경험해보셨을 겁니다. 이 이유가 재귀를 반복적으로 호출하면서 Stack 메모리 영역에 해당 함수의 지역변수, 매개변수들이 계속 할당되다가 OS에서 할당해준 Stack영역의 메모리 영역을 넘어버리면 발생하는 오류입니다.
Stack영역은 Heap영역과 반대로 높은주소에서 낮은주소로 메모리에 할당됩니다.
이렇게 4가지 영역을 간단하게 알아보았습니다. 하지만 아직 설명하지 않은 것이 있죠. 위 이미지를 보면 메모리 모양 옆에 Low address, High address가 있을 겁니다.
이 것 또한 4가지 영역과 관련이 있습니다. 실제로 Data영역들은 낮은 주소에 할당되고, Heap, Stack의 경우는 비교적 높은 주소에 할당되거든요.
일단, 이를 설명하기 전에 메모리 주소에 대해 잠깐 보고 가보죠.
- 메모리 주소 (Memory Address)
여러분들이 게임이나 어떤 프로그램을 다운로드 할 때 한 번쯤은 반드시 들어봤을 단어가 있습니다.
'32bit 운영체제 용', '64bit 운영체제 용'
또는 Windows 운영체제 사용자들 대다수가 한 번쯤을 봤을 x86(32비트) 또는 x64(64비트) 가 있죠.
이 둘의 차이점을 아주 간단하게 말하자면 비트의 너비(폭)이라고 보시면 됩니다. 비유하자면 고속도로에 32개의 차선이 있는데 이를 더 넓혀 64개의 차선으로 만든 것이죠. 직관적으로 말하자면 데이터 처리 단위라고 보시면 됩니다.
그리고 32개의 비트가 있다는 것은 0000 0000 0000 0000 0000 0000 0000 0000 부터 1111 1111 1111 1111 1111 1111 1111 1111 까지, 그러니까 232의 경우의 수를 갖고,
64개의 비트가 있다는 것은 264의 경우의 수를 갖는다는 것이죠.
이 둘의 차이는 생각보다 엄청나게 큽니다.
232 = 4,294,967,296 (약 43억)
264 = 18,446,744,073,709,551,616 (약 1844경)
64bit 운영체제가 데이터 처리 단위가 더 많다보니 당연히 CPU 처리도 고속화 되고, 새로운 명령어들도 만들 수 있죠. 그렇다보니 64bit 운영체제에서는 32bit프로그램을 돌릴 수가 있지만, 32bit에서는 64bit용 프로그램을 돌릴 수가 없는 것입니다.
그럼 32bit와 64bit를 설명하느냐?
이 것이 바로 메모리와도 연관이 있기 때문입니다. (참고로 바이트 표기법은 사실 우리가 아는 표현 방식이 아닌, KiB, MiB, GiB, TiB 등이 맞지만 익숙 한 것은 KB, MB, GB, TB 가 익숙할테니 여기 한 정하여 해당 표현으로 대체하겠습니다.)
메모리 한칸은 1byte의 크기를 갖고 있습니다. 그리고 32bit 운영체제에서는 32개의 비트, 즉 4바이트 길이의 주소를 갖습니다. 쉽게 말하자면 집 평수는 1평이고, 이 집을 가리키는 주소는 32자리로 표현된다고 보시면 됩니다. (길이와 크기를 혼동하시면 안됩니다.)
그리고 232까지의 경우의 수가 있으니, 4,294,967,296 개의 주소를 가리킬 수 있다는 의미이고, 이는 1바이트 크기의 메모리가 4,294,967,296 개 까지 인식이 가능하다는 것, 즉 메모리의 최대 크기는 4,294,967,296 byte = 4GB 이죠. 옛날 32bit 운영체제가 대다수인 시절 메모리를 4GB까지밖에 설치 할 수 없는 이유가 여기서 나오는 것이죠.
그럼 64bit 운영체제는 어떨까요? 64bit 는 8바이트이므로 하나의 주소가 8바이트 길이의 주소를 갖는다는 것을 알 수 있겠죠? 그리고 마찬가지로 264개. 즉, 18,446,744,073,709,551,616 개의 주소를 가리킬 수 있다는 의미고 이는 18,446,744,073,709,551,616 byte = 16EB(엑사바이트) = 16384PB(페타바이트) = 16777216TB(테라바이트) 까지 입니다.
(정확히는 16EiB = 16384PiB = 16777216TiB 이죠.)
한 마디로 이론적으로는 램을 16EB까지 설치 할 수 있다는 것이죠. (엑사바이트는 페타바이트의 1024배입니다.)
(참고로 아직 16EB를 지원하는 OS는 없고 제가 알기로는 리눅스에서 8EB까지 지원하는 버전이 있다고는 들었습니다. 메인보드에서도 지원 한계량이 있어서.. 그렇다고는 해도 아직까지는 충분한 양입니다. 요즘에는 대부분 32GB 또는 64GB까지는 지원하는 것 같더군요.)
엄청난 차이라는 것을 볼 수 있겠죠?
하지만 이 주소를 2진수로 표현하기에는 너무 길어 우리는 보통 편의상 16진수로 표현합니다.
32bit에서는 0x00000000 ~ 0xFFFFFFFF
64bit에서는 0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF
이렇게 말이죠.
두 메모리를 좀 더 구체적으로 보자면 이렇게 됩니다.

요즘은 어떨지 모르겠지만, 보통 C언어에서 포인터(pointer)에 대해 배울 때 포인터는 메모리 공간 주소를 가리키는 변수이고, "모든 포인터는 모두 4byte의 동일한 크기를 갖는다." 라고 배우지만 이는 사실 32bit 운영체제에 한정해서 사실인 것이죠.
위에서 배운 내용을 생각해보면 포인터는 '주소'를 가리키기 때문에 운영체제가 몇비트이냐에 따라 달라집니다. 주소의 길이가 달라집니다. 32bit에서는 포인터의 크기가 4byte라면, 64bit에서는 주소의 길이가 8byte이기 떄문에 당연하게도 포인터의 크기 또한 8byte일 수밖에 없죠.
더군다나 요즘은 아주 오래된 컴퓨터가 아니면 64bit 운영체제이기 때문에 '운영체제 비트에 따라 포인터의 크기가 달라진다' 라고 배우거나, '보통의 경우 포인터는 8byte의 크기를 갖는다'로 가르치는 것이 앞으로의 대세가 되지 않을까 싶습니다.
(애플도 카탈리나부터 32bit 프로그램 지원을 중단했고, 확실하게 32bit 운영체제는 한계가 많기 때문이죠.)
이렇게 메모리의 구조를 살짝이나마 알아보았습니다.
그리고 이 다음 설명부터는 64bit 를 기준으로 설명하도록 하겠습니다.
다시 복기하고 넘어가자면 메모리 한 칸의 크기는 1바이트다.
64비트 운영체제는 메모리 한 칸의 주소를 64비트로 표현하며 이는 8바이트와 같은 의미이고, 메모리 주소를 8바이트로 표현하기 때문에 포인터(주소를 가리키는 변수)의 크기 또한 8바이트이다.
- 코드와 메모리 영역 (Code and Memory Layout)
앞서 메모리 구조는 통상 Text, Data, Heap, Stack 으로 구분된다고 했습니다. 다시 한 번 그림을 보자면 이렇습니다.

그러면 실제로 어떻게 저장되는지 아주 간단하게 코드와 메모리를 한 번 보도록 하죠.
메모리에 대해 배우는만큼 오늘은 C언어로 작성하겠지만, 크게 어려운 것은 없으니 C언어를 모르셔도 괜찮습니다.

위 이미지처럼 상수, 함수는 Text 영역에, 전역, 정적변수는 Data 영역에, 지역변수들은 Stack 영역에, 동적할당이 되는 변수들은 Heap영역에 위치하게 됩니다. (참고로 malloc 함수는 런타임(실행중)에 메모리를 동적으로 할당할 수 있는 함수라는 것 정도로만 알아두셔도 됩니다.)
쉽게 생각하면 위 4개의 영역 중 Text영역이 가장 낮은 주소(0에 가까운 주소), Data영역이 그 다음 주소, Heap영역이 Data영역의 다음 주소, Stack영역은 4개 영역 중 가장 높은 주소에 위치한다고 보면 되죠.
실제로 그러면 저 4개의 영역에 해당되는 변수들의 메모리가 어떻게 할당되었는를 검증해야겠죠?
C, C++언어는 '포인터'란 개념이 있습니다. '메모리 주소를 가리키는 변수'라고 보시면 됩니다.
그리고 해당 메모리 주소를 출력하는 방법은 %p 을 쓰시면 됩니다.
위 코드에서 각각의 변수 및 함수들의 주소를 출력해보도록 하죠. 코드는 아래와 같습니다.
|
|
#include <stdio.h> |
|
|
#include <stdlib.h> |
|
|
|
|
|
const int constval = 30; // 상수 |
|
|
|
|
|
int uninitial; // 초기화되지 않은 전역변수 |
|
|
int initial = 30; // 초기화된 전역변수 |
|
|
static int staticval = 70; // 정적변수 |
|
|
|
|
|
|
|
|
int function() { // 함수 |
|
|
return 20; |
|
|
} |
|
|
|
|
|
|
|
|
int main(int argc, const char * argv[]) { |
|
|
|
|
|
int localval1 = 30; // 지역변수 1 |
|
|
int localval2; // 지역변수 2 |
|
|
|
|
|
printf("숫자 입력 : "); |
|
|
scanf("%d", &localval2); |
|
|
|
|
|
char *arr = malloc(sizeof(char) * 10); // 동적 할당 변수 |
|
|
|
|
|
|
|
|
|
|
|
/* 포인터 출력 영역 */ |
|
|
printf("상수 Memory Address : \t\t %p \n", &constval); |
|
|
printf("비초기화 변수 Memory Address :\t %p \n", &uninitial); |
|
|
printf("초기화 변수 Memory Address : \t %p \n", &initial); |
|
|
printf("정적 변수 Memory Address : \t %p \n", &staticval); |
|
|
printf("함수 Memory Address : \t\t %p \n", function); |
|
|
printf("지역변수1 Memory Address : \t %p \n", &localval1); |
|
|
printf("지역변수2 Memory Address : \t %p \n", &localval2); |
|
|
printf("동적할당변수 Memory Address : \t %p \n\n", arr); |
|
|
|
|
|
|
|
|
return 0; |
|
|
} |
위 코드를 실행해보면 필자의 경우 이러한 결과가 나타납니다.

저랑 결과값이 다르다고 문제있는 것이 아니니 걱정하지 마시기 바랍니다. 코드, 시스템, 실행환경 등에 따라 얼마든지 메모리주소는 달라질 수 있습니다.
(사실 위 주소는 정확히 말하면 실제 물리적 메모리의 주소는 아닙니다만, 메모리 구조를 알아가는데 문제는 크게 없습니다.
가상메모리와 페이징라는 것이 있는데 이 내용은 본 내용의 난이도와 주제를 고려하여 따로 설명하지는 않을겁니다.
간단한 코멘트를 보시고 싶으시면 아래 더 보기를 누르시면 되겠습니다.)
다만, 여기서 우리가 중점적으로 봐야 할 점은 실제로 앞서 배웠던 메모리에 할당되는 위치와 같은 유사한 구조를 지니느냐겠죠.
먼저 저는 64bit으로 컴파일했습니다. 이 말은 64비트(=8byte) 길이의 주소를 갖는다고 했죠. 이진수로 표기하면 자리수가 64개인데 이는 표기하기엔 너무 길기 때문에 16진수로 표현하면 16자리수로 표현할 수 있습니다.(2진수의 4자리 묶음당 16진수의 한 자리가 됩니다)
참고로 높은자리수의 0은 생략되어 출력됩니다. 그러니까 상수의 메모리 주소값인 0x100000e64 의 경우 정확하게 모두 표현하자면 0x0000000100000e64 가 되는 것이죠.
보기 편하게 16자리로 채워서 보도록 하죠. (코드를 조금 수정해서 메모리주소가 조금씩 변한 것을 볼 수 있죠?)

먼저 상수는 Text영역이라고 했습니다. 보면 다른 변수들과 비교했을 때 가장 낮은주소에 위치하는 것을 보실 수 있습니다.
전역변수는 제가 두 가지로 나누어봤었죠. 이미 초기화된 변수와 초기화되지 않은 변수로 말이죠. 위 주소를 보면 상수보다는 높은 주소에, Heap영역인 동적할당변수보다는 낮은주소에 위치한다는 것을 볼 수 있습니다. Data영역에 맞게 할당된 것 같군요. (참고로 먼저 초기화 된 변수들이 더 낮은주소에 위치하고 모두 메모리에 올려지면 그 다음으로 초기화가 안된 변수들이 할당됩니다.
정적변수 또한 전역변수와 마찬가지로 Data영역으로 상수 영역에 있는 데이터보단 높은 주소에, Heap영역에 있는 데이터 주소보단 낮은 주소에 자리하고 있습니다.
함수는 상수와 마찬가지로 Text영역입니다. 보면 Data 영역보다 낮은 주소에 위치하고 있죠. 상수와 거의 유사한 주소에 위치하는 것을 볼 수 있죠? 그럼 만약 함수안에 있는 변수들은 어떻게 될까요? 먼저 Text영역에 있는 함수를 호출함과 동시에 내부에 있는 변수들은 Stack영역에 할당하게 됩니다. 그리고 해당 함수가 종료되면 Stack메모리에 있던 함수의 변수들은 모두 pop됩니다.
지역변수의 경우 Stack영역이라고 했습니다. Stack영역은 다른 영역과는 다르게 높은주소에서 낮은 주소로 메모리에 할당됩니다. 즉, 어느정도 높은 주소부터 시작하여 지역변수들이 선언될 때마다 낮은주소로 쌓입니다. 이를 확인하기 위해 2개의 지역변수를 선언했던 것이죠. 보시다시피 먼저 선언한 지역변수1은 0x7ffeefbff47c 이고, 그 다음으로 선언된 지역변수2는 int형 변수이므로 4byte의 크기이니 4칸만큼 작은 주소인 0x7ffeefbff478에 위치하는 것을 볼 수 있습니다.
마지막으로 동적할당 변수의 경우 Heap영역이라고 했습니다. 보시면 Text, Data보다는 비교적 높은 주소에서 시작하지만, Stack영역에 비해서는 한없이 작은 주소에서 시작하는 것을 볼 수 있습니다.
그럼 한 번 메모리에 어떻게 할당되었는지 보도록 하죠.
저는 XCode를 사용하고 있기 때문에 이를 통해서 보겠습니다. (윈도우의 경우 Visual Studio에서 보실 수 있습니다.)
1. 상수

제 코드에서는 상수를 int타입으로, 값은 30으로 초기화 했었습니다.
그리고 해당 상수의 메모리 주소는 0x100000e64였죠.(= 0x0000000100000e64)
int는 4byte의 크기를 갖기 때문에 메모리 4칸을 차지하게 되고, 보시다시피 해당 메모리 영역에 1E 00 00 00 에 해당 된 걸 볼 수 있습니다.
쉽게 생각하자면 이렇습니다. 30이 이진수로는 0001 1110 이고 이를 16진법으로 바꾸면 1E라는 것은 알겁니다.

다른 변수들도 한 번 체크해볼까요?
[uninitial]

별달리 초기화하지 않았기 때문에 0으로 초기화해준 걸 볼 수 있습니다.
[initial]
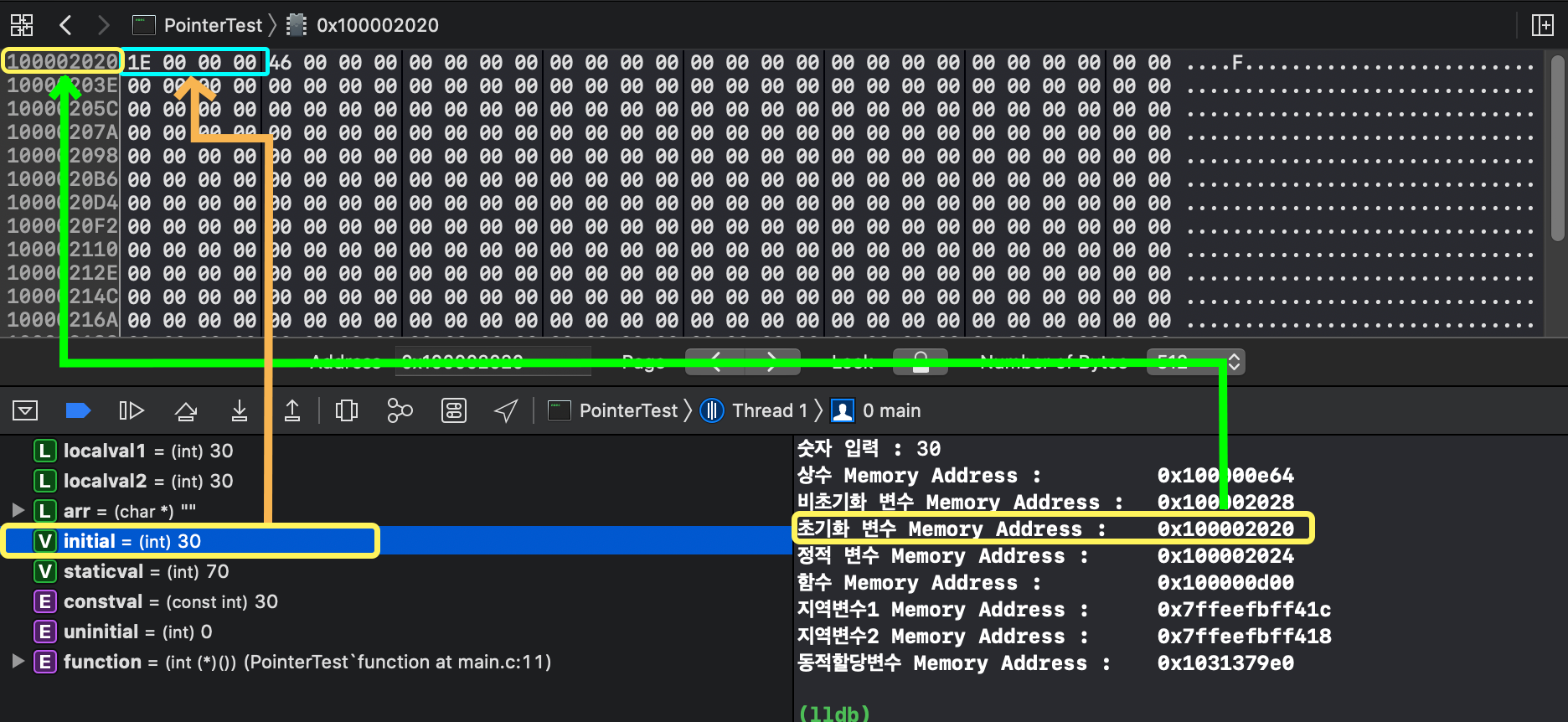
[static]

[function]

포인터는 말 그대로 '시작 주소'를 가리키기 때문에 함수의 전체(구조) 크기는 알기가 매우 힘듭니다. 만약 두 함수가 인접한 메모리에 있다면 대략이나마 유추는 가능하겠지만 정확히 알기는 어렵죠. 그래서 메모리에 별다른 박스는 해놓지 않았습니다.
[localval1 & localval2]

보시다시피 선언순서는 localval1, localval2 순서대로 생성했지만, 지역변수는 Stack 영역이라 가장 나중에 생성된 변수가 더 낮은 주소에 위치하는 것을 볼 수 있죠.
[동적할당변수]

앞서 우리는 동적할당을 할 때 char(1byte) 사이즈의 곱하기 10배를 한 값으로 할당을 해주었습니다. 즉, 10byte의 메모리를 잡아준 것이죠.
다만, 유의해야할 점은 동적할당을 해주는 malloc은 '메모리를 할당'해줄 뿐 초기화는 해주지 않기 때문에 일명 쓰레기값이 들어있는 상태입니다. 4A나 2F가 바로 쓰레기 값(Garbage value)인 것이죠.
|
|
for(int i = 0; i < 10; i++){ |
|
|
arr[i] = i; |
|
|
} |
만약 이렇게 변수를 초기화를 한다고 하면, 다음과 같이 값이 변한 것을 볼 수 있습니다.

(만약 처음 동적할당 할 때 초기값을 설정해주고 싶다면 calloc() 함수를 사용하면 됩니다.)
- Buffer Overflow
아마 코딩을 하신 분이라면 한 번쯤은 마주했거나 앞으로 한 번쯤은 반드시 마주하게 될 대표적인 에러입니다. 보안에 관심있는 분들이라면 들어보셨을 겁니다.
일단 설명을 하자면 Buffer Overflow는 직역한 그대로 버퍼(Buffer)를 넘치게(overflow)하게 되는 상태를 말합니다. 여기서 Buffer는 보통 메모리를 의미하구요. 또 다른 말로는 Buffer Overrun 이라고도 합니다.
앞서 우리가 메모리에서 4가지 영역으로 구분하여 살펴보았는데, 그 중 가장 대표적인 Heap과 Stack 영역입니다.
왜 대표적인 영역일까요? 바로 Stack과 Heap은 프로그램이 실행하면서 생성되는 데이터들이 저장되는 공간입니다. 해당 영역의 버퍼를 인위적으로 넘치게 만들어 인접한 데이터 영역까지 침범하게 만들고 결국 포인터 영역까지 침범하게 되는데 이 때 특정 명령을 넣어 프로그램을 붕괴시키거나 시스템의 권한을 상승시킬 수 있죠.
물론 영역 간의 침범만이 Overflow 인 것은 절대 아닙니다.
예로들어 메모리에 할당 된 변수의 크기보다 더 큰 데이터를 입력시키는 경우도 Overflow 라고 합니다. C언어에서는 대표적으로 데이터의 크기를 검사하지 않는 함수들인 strcpy(), gets(), scanf() 등이 있죠.
즉, Overflow라는 큰 범주 안에 Heap Overflow, Stack Overflow 들이 있고 그 안에서도 데이터 버퍼의 Overflow와 메모리 영역에 대한 Overflow가 있습니다.
하지만, 오늘은 메모리에 대한 내용인만큼 '영역'에 초점을 두고 설명하고자 합니다. 그렇기에 Buffer Overflow에 대해 자세히 다루기 보다는, 알고리즘을 풀면서 주로 겪는 경우들을 중심으로 살펴보려고 합니다.
또한 여러분이 어떤 개발도구를 사용하고, 어떤 언어를 사용하느냐에 따라 에러 메세지가 조금씩 다를 수 있고, 어떨때는 그냥 프로그램을 중단시켜버릴 수도 있습니다만, 보통 Stack Overflow와 Heap Overflow로 통일하여 설명하겠습니다.
그럼 하나씩 짚어봅시다.
Stack Overflow
Stack Overflow는 호출 스택이 할당 된 스택 영역 경계선 밖으로 넘어갈 때 발생합니다. 보통 가장 흔히 발생하는 경우는 '재귀호출'에서 발생합니다.
가장 쉬운 예로 재귀를 탈출 없이 무한 호출하도록 코드를 짜보죠.
|
|
#include <stdio.h> |
|
|
int count = 1; |
|
|
|
|
|
void func() { |
|
|
int a = 1; |
|
|
int b = 2; |
|
|
|
|
|
printf("depth : %d\ta : %p\tb : %p\n", count, &a, &b); |
|
|
count++; |
|
|
func(); |
|
|
} |
|
|
|
|
|
int main(int argc, const char * argv[]) { |
|
|
func(); |
|
|
} |
이를 어셈블리어로 뜯어보면 func() 함수의 동작은 아래와 같습니다.

어떤 명령인지는 몰라도 괜찮습니다. 딱 필요한 부분만 간단하게 설명해주도록 하기 위해 이미지를 올린 것입니다.
여기서 조금만 정리해서 딱 필요한 부분만 추출하자면 이렇습니다.
|
|
0x100000f10 <+0>: pushq %rbp // 스택에 push |
|
|
0x100000f11 <+1>: movq %rsp, %rbp // 첫번 째 인자에 두번 쨰 인자 값 복사 |
|
|
0x100000f14 <+4>: subq $0x10, %rsp // 두 번째 인자에 첫 번째 인자만큼 뺄셈 |
|
|
0x100000f18 <+8>: movl $0x1, -0x4(%rbp) |
|
|
0x100000f1f <+15>: movl $0x2, -0x8(%rbp) |
|
|
0x100000f54 <+68>: callq 0x100000f10 ; <+0> at main.c:12 |
|
|
0x100000f59 <+73>: addq $0x10, %rsp |
|
|
0x100000f5d <+77>: popq %rbp |
|
|
0x100000f5e <+78>: retq |
%rbp : 스택의 시작점을 가리킵니다.
%rsp : 스택의 꼭대기를 가리킵니다.
pushq %rbp : 스택에 %rbp을 밀어넣습니다.
movq %rsp, %rbp : %rsp 에 %rbp의 값을 복사합니다.
subq $0x10 %rsp : srp를 16(0x10 = 16)만큼 뺍니다.
movl $0x1, -0x4(%rbp) : %rbp에서 4만큼 뺀 위치에 1(0x01)의 값을 복사합니다.
callq 0x100000f10 : 다음에 실행할 명령어 주소를 스택에 저장하고 인자로 받은 주소(0x100000f10)로 이동
일단 여러분이 보아야 할 것은 이 것밖에 없습니다.
조금은 어려워 보이지만, 가장 중요한 부분을 아주아주 쉽게 설명드리자면 이렇습니다.
1. 먼저 스택의 시작점(%rbp)을 스택에 넣습니다(pushq) (64bit이니 8바이트만큼 스택에 저장됩니다.)
2. 스택의 꼭대기 지점(%rsp)을 스택의 시작점(%rbp) 값을 복사한 다음
3. 스택의 꼭대기 지점(%srp)을 16(0x10) 을 빼줍니다.
↳ 이는 스택의 시작점에서 10의 주소만큼 빼준 것이 스택의 꼭대기가 된다는 것이죠? 여기서 잘 생각해봅시다. 스택영역은 '높은 주소'에서 '낮은 주소'로 이동한다고 했습니다. 한마디로 스택의 꼭지점이 16만큼 감소했다는 것은 16바이트 크기만큼 할당을 해줬다는 얘기이기도 합니다. 즉, func()함수가 한 번 실행될 때 fun()함수 내부에서는 16바이트 크기만큼 쓰인다는 것입니다.
4. 스택의 시작점(%rbp)에서 -4의 위치(-0x4)에 1(0x1) 값을 복사합나다. 이는 우리가 코드에서 작성한 int a = 1; 부분이겠죠.
5. 스택의 시작점(%rbp)에서 -8의 위치(-0x8)에 2(0x2) 값을 복사합나다. 이는 우리가 코드에서 작성한 int b = 2; 부분이겠죠.
그리고 마지막으로 callq에 의해 0x100000f10으로 이동합니다. 이 때 앞서 설명했듯 다음 명령어 주소를 스택에 저장한 뒤 이동한다고 했습니다. 즉, 0x100000f59가 스택에 push되겠죠. 그리고 이동하는 곳은 0x100000f10은 func() 함수의 시작 명령어 위치라는 것을 볼 수 있죠.
그럼 정리해보죠. 맨 처음 주소값(8바이트) + 함수 내부 할당(16바이트) + 다음 명령 주소값(8바이트) = 총 32바이트입니다. 16진수로 보자면 0x20가 되겠죠.
위 명령 구조를 보면 결국엔 마지막 세 줄은 실행되지 않은채 0x100000f10 으로 이동하면서(재귀) 실행할 때마다 stack메모리에는 계속 값이 push 만 되고, pop되진 않습니다.
좀 더 정확히 보면 매번 함수가 재귀적으로 호출 될 때마다 스택에 32바이트씩 쌓이고 있다는 것을 알 수 있죠.
실재로 저 코드를 실행시키면 각 카운트마다 변수의 주소가 32씩 변하는 것을 볼 수 있습니다.

이렇게 무한히 stack 영역에 데이터가 push되다가 Stack영역을 넘어가버리게 되면 바로 Stack Overflow가 발생하는 것입니다.
(구체적으로 메모리에 어떻게 쌓이는지 보고싶은 분은 아래 더 보기를 눌러주시면 됩니다.)
이렇게 어떤 할당된 공간을 넘어서게 되면 overflow 가 발생한다고하고, 그 에러가 Stack에서 발생한 경우 Stack Overflow라고 하는 것입니다.
하나의 그림으로 정리하자면 아래와 같겠네요.

이렇게 Stack Overflow 가 발생하는 것을 방지하기 위해서는 재귀를 되도록 피하는 것이 좋겠죠.
Heap Overflow
Heap Overflow는 힙 영역에서 할당 된 영역의 경계선 밖으로 넘어갈 때 발생합니다. 가장 흔히 발생하는 경우는 매우 큰 데이터를 생성하려고 할 때 발생합니다.
자바를 접해보신 분들은 아마 이런 표현이 익숙하실 겁니다. OutOfMemory 에러, 메모리 부족이라고도 합니다.
스택과 마찬가지로 Heap영역보다 큰 데이터가 들어올 경우 발생하는데, Stack에서는 지역변수들이 스택에 쌓인다면, 반대로 Heap 영역에서는 동적으로 관리되는 데이터들이 일정 공간 이상 차지하게 될 경우 발생하는 것이죠.
각 언어마다 Heap 에서 관리하는 데이터는 조금씩 상이합니다만, 대표적으로 malloc()같은 동적 할당 함수, 객체, 참조변수들이 Heap 영역에서 관리됩니다.
대표적으로 C 언어에서는 new 연산자가 없습니다. 그래서 int[] 같은 배열의 경우 전역, 정적변수가 아닌이상 Stack 영역에 쌓이거나 동적할당을 하고싶은 경우 malloc() 같은 함수를 쓰죠. 반대로 C++나 Java같은 경우는 new연산자를 지원하고 있어 하나의 객체로 Heap영역에서 관리될 수 있게 하고 있습니다.
|
|
int arr[10]; // C, C++ : Stack 영역 |
|
|
int *arr = new int[10] // C++ : Heap 영역 |
|
|
int[] arr = new int[10] // Java : Heap 영역 |
이런 차이가 있기 때문에 미리 인지하고 가시는게 좋을 것 같습니다.
자 그럼, Heap 영역을 넘치게 하는 가장 쉬운 방법은 무엇일까요? 가장 쉬운 방법은 아주아주 큰 배열을 생성하는 것이죠. C언어에서는 malloc()으로, C++나 Java에서는 new라는 키워드를 사용하여 생성하면 됩니다.
XCode의 경우는 에러 원인을 상세하게 볼 수 없어서 이 번에는 Eclipse에서 Java를 이용하여 보여주겠습니다.

(Integer.MAX_VALUE 는 int형의 최댓값인 2,147,483,647 을 의미합니다. 그 수에 -2를 해주는 이유는 Java의 VM에서 배열 크기 최대 한도를 2,147,483,645 으로 제한했기 때문입니다.)
보면 아래 빨간색 글씨로 "Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at HeapMemoryTest.main()" 이라고 뜨죠?
쉽게 말하자면 JVM에서 쓰는 Heap 영역 밖을 넘어섰다는 것입니다.
생각해보면 이렇습니다. int형은 4바이트 크기를 갖고 있습니다. 그 공간을 2,147,483,645 개를 만든다는 것은 다음과 같겠죠.
4 * 2,147,483,645 = 8589934580 바이트 = 약 8GB
결코 적지 않은 용량이죠.
이렇게 Heap 영역을 넘어가서 에러가 발생하는 경우가 생각보다 많이 있습니다. 그나마 Java에서는 JVM(자바 가상머신)이 더이상 참조되지 않는 데이터들의 경우 알아서 메모리를 반납해주는 GC(Garbage Collector : 가비지 컬렉터)가 있기 때문에 Heap 메모리 관리에 보다 수월하지만, C, C++같은 경우는 GC가 따로 없기 때문에 반드시 더이상 쓰지 않는 동적 할당 변수들을 해제해주어야 합니다.
만약 해제 하지 않는 경우 흔히 말하는 메모리 누수(Memory Leak)가 발생하는 것이죠.
또한 동적으로 관리해야 하는 변수들의 경우 어느정도 크기를 예측하고 제한할 수 있어야 힙 메모리가 부족한 현상이 안오겠죠?
Heap 영역에서의 Overflow는 다음과 같이 볼 수 있겠네요.

이렇게 Heap에서 관리되는 변수들을 쓸 때에는 (특히 C, C++) 더이상 사용하지 않는 동적할당 변수들을 정확하게 해제해야한다는 점 알아두시기 바랍니다.
- 정리하기
글을 쓰다보니 엄청 길어졌네요.. 사실 이번 파트의 경우 A라는 것을 알려주려 하면 B도 알아야하고, C도 알아야하고... 이렇다보니 최대한 압축 시켰다 하더라도 글이 길어져버렸습니다.
나중에 구체적으로 배우게 되면 알겠지만, 이 내용으로는 턱없이 부족하실 겁니다. 추상적이고 대표적인 것들만 추린 것들이라 만약 메모리 구조에 대해 이미 배우셨다면 "이 거 말고도 더있는데?!" 하실 수도 있을겁니다.
하지만, 제 목적은 어느정도 '언어'자체는 배웠지만, 프로그래밍에 대한 전체적인 구조를 알기 위한 것인지라 더 깊게는 안 들어가려고 합니다.
이 번 포스팅의 경우 메모리의 메커니즘에 대해 깊게 보단 넓게 다루었다고 봐주시면 감사할 것 같네요 :)
내용이 조금 어려웠을 수도 있는지라 언제든 모르는 것이 있다면 댓글 남겨주시길 바랍니다. 물론 오타나 잘못된 것에 대한 지적도 언제나 환영입니다.
[출처] Ergonomics
https://docs.oracle.com/en/java/javase/11/gctuning/ergonomics.html#GUID-DB4CAE94-2041-4A16-90EC-6AE3D91EC1F1
2 Ergonomics
Ergonomics is the process by which the Java Virtual Machine (JVM) and garbage collection heuristics, such as behavior-based heuristics, improve application performance.
The JVM provides platform-dependent default selections for the garbage collector, heap size, and runtime compiler. These selections match the needs of different types of applications while requiring less command-line tuning. In addition, behavior-based tuning dynamically optimizes the sizes of the heap to meet a specified behavior of the application.
This section describes these default selections and behavior-based tuning. Use these defaults before using the more detailed controls described in subsequent sections.
Garbage Collector, Heap, and Runtime Compiler Default Selections
These are important garbage collector, heap size, and runtime compiler default selections:
- Garbage-First (G1) collector
- The maximum number of GC threads is limited by heap size and available CPU resources
- Initial heap size of 1/64 of physical memory
- Maximum heap size of 1/4 of physical memory
- Tiered compiler, using both C1 and C2
Behavior-Based Tuning
The Java HotSpot VM garbage collectors can be configured to preferentially meet one of two goals: maximum pause-time and application throughput. If the preferred goal is met, the collectors will try to maximize the other. Naturally, these goals can't always be met: Applications require a minimum heap to hold at least all of the live data, and other configuration might preclude reaching some or all of the desired goals.
Maximum Pause-Time Goal
The pause time is the duration during which the garbage collector stops the application and recovers space that's no longer in use. The intent of the maximum pause-time goal is to limit the longest of these pauses.
An average time for pauses and a variance on that average is maintained by the garbage collector. The average is taken from the start of the execution, but it's weighted so that more recent pauses count more heavily. If the average plus the variance of the pause-time is greater than the maximum pause-time goal, then the garbage collector considers that the goal isn't being met.
The maximum pause-time goal is specified with the command-line option -XX:MaxGCPauseMillis=<nnn>. This is interpreted as a hint to the garbage collector that a pause-time of <nnn> milliseconds or fewer is desired. The garbage collector adjusts the Java heap size and other parameters related to garbage collection in an attempt to keep garbage collection pauses shorter than <nnn> milliseconds. The default for the maximum pause-time goal varies by collector. These adjustments may cause garbage collection to occur more frequently, reducing the overall throughput of the application. In some cases, though, the desired pause-time goal can't be met.
Throughput Goal
The throughput goal is measured in terms of the time spent collecting garbage, and the time spent outside of garbage collection is theapplication time.
The goal is specified by the command-line option -XX:GCTimeRatio=nnn. The ratio of garbage collection time to application time is 1/ (1+nnn). For example, -XX:GCTimeRatio=19 sets a goal of 1/20th or 5% of the total time for garbage collection.
The time spent in garbage collection is the total time for all garbage collection induced pauses. If the throughput goal isn't being met, then one possible action for the garbage collector is to increase the size of the heap so that the time spent in the application between collection pauses can be longer.
Footprint
If the throughput and maximum pause-time goals have been met, then the garbage collector reduces the size of the heap until one of the goals (invariably the throughput goal) can't be met. The minimum and maximum heap sizes that the garbage collector can use can be set using -Xms=<nnn> and -Xmx=<mmm> for minimum and maximum heap size respectively.
Tuning Strategy
The heap grows or shrinks to a size that supports the chosen throughput goal. Learn about heap tuning strategies such as choosing a maximum heap size, and choosing maximum pause-time goal.
Don't choose a maximum value for the heap unless you know that you need a heap greater than the default maximum heap size. Choose a throughput goal that's sufficient for your application.
A change in the application's behavior can cause the heap to grow or shrink. For example, if the application starts allocating at a higher rate, then the heap grows to maintain the same throughput.
If the heap grows to its maximum size and the throughput goal isn't being met, then the maximum heap size is too small for the throughput goal. Set the maximum heap size to a value that's close to the total physical memory on the platform, but doesn't cause swapping of the application. Execute the application again. If the throughput goal still isn't met, then the goal for the application time is too high for the available memory on the platform.
If the throughput goal can be met, but pauses are too long, then select a maximum pause-time goal. Choosing a maximum pause-time goal may mean that your throughput goal won't be met, so choose values that are an acceptable compromise for the application.
It's typical that the size of the heap oscillates as the garbage collector tries to satisfy competing goals. This is true even if the application has reached a steady state. The pressure to achieve a throughput goal (which may require a larger heap) competes with the goals for a maximum pause-time and a minimum footprint (which both may require a small heap).
'프로그램 개발(분석, 설계, 코딩, 배포) > 2.2.1 java' 카테고리의 다른 글
| JDBC 90405 에러 (0) | 2025.01.31 |
|---|---|
| Spring Framework / Spring Boot의 차이 (1) | 2024.12.02 |
| spring 과 springBoot의 차이점 (0) | 2024.12.02 |
| [Java] Spring Boot - 스프링 부트 3 버전 (1) | 2024.11.30 |
| [Java] Spring Boot 2.x.x 버전 프로젝트 생성: 지원 종료 및 다운그레이드 (0) | 2024.11.30 |