BigData/Parquet2023. 1. 5. 01:34
- 목차
Header - Metadata offset & Length.
관련된 글
https://westlife0615.tistory.com/333
- 목차 관련된 글 https://westlife0615.tistory.com/332 Avro File 알아보기 - 목차 소개. Avro 는 두가지 기능을 제공합니다. 첫번째는 직렬화 기능입니다. Avro 는 Serialization Framework 로서 직렬화와 역직렬화를
https://westlife0615.tistory.com/445
<?xml version="1.0" encoding="UTF-8" ?>
0000000 624f 016a 0a06 776f 656e 1872 6577 7473
0000010 696c 6566 3630 3531 6114 7276 2e6f 6f63
0000020 6564 0863 756e 6c6c 6116 7276 2e6f 6373
0000030 6568 616d 01e2 227b 616e 656d 7073 6361
0000040 2265 203a 6522 6178 706d 656c 612e 7276
0000050 226f 202c 7422 7079 2265 203a 7222 6365
0000060 726f 2264 202c 6e22 6d61 2265 203a 5522
0000070 6573 2272 202c 6622 6569 646c 2273 203a
0000080 7b5b 6e22 6d61 2265 203a 6e22 6c75 616c
0000090 6c62 2265 202c 7422 7079 2265 203a 6e22
00000a0 6c75 226c 5d7d 007d 5168 dc6c a5ed 16b8
00000b0 33a1 de93 98d6 bcec 8980 007a 5168 dc6c
00000c0 a5ed 16b8 33a1 de93 98d6 bcec
Parquet 는 위 Avro 파일처럼 바이너리 형식의 파일 포맷입니다.
이어질 내용에서 자세히 알아보도록 하겠습니다.
00000000 4f 62 6a 01 06 0a 6f 77 6e 65 72 18 77 65 73 74 |Obj...owner.west|
00000010 6c 69 66 65 30 36 31 35 14 61 76 72 6f 2e 63 6f |life0615.avro.co|
00000020 64 65 63 08 6e 75 6c 6c 16 61 76 72 6f 2e 73 63 |dec.null.avro.sc|
00000030 68 65 6d 61 9e 02 7b 22 6e 61 6d 65 73 70 61 63 |hema..{"namespac|
00000040 65 22 3a 20 22 65 78 61 6d 70 6c 65 2e 61 76 72 |e": "example.avr|
00000050 6f 22 2c 20 22 74 79 70 65 22 3a 20 22 72 65 63 |o", "type": "rec|
00000060 6f 72 64 22 2c 20 22 6e 61 6d 65 22 3a 20 22 55 |ord", "name": "U|
00000070 73 65 72 22 2c 20 22 66 69 65 6c 64 73 22 3a 20 |ser", "fields": |
00000080 5b 7b 22 6e 61 6d 65 22 3a 20 22 6e 61 6d 65 22 |[{"name": "name"|
00000090 2c 20 22 74 79 70 65 22 3a 20 22 73 74 72 69 6e |, "type": "strin|
000000a0 67 22 7d 2c 20 7b 22 6e 61 6d 65 22 3a 20 22 61 |g"}, {"name": "a|
000000b0 67 65 22 2c 20 22 74 79 70 65 22 3a 20 22 69 6e |ge", "type": "in|
000000c0 74 22 7d 5d 7d 00 b7 bc a4 f7 87 42 1f a9 70 ab |t"}]}......B..p.|
000000d0 f6 a5 83 c2 63 a2 08 56 10 77 65 73 74 6c 69 66 |....c..V.westlif|
000000e0 65 3c 12 77 65 73 74 6c 69 66 65 31 3e 12 77 65 |e<.westlife1>.we|
000000f0 73 74 6c 69 66 65 32 40 12 77 65 73 74 6c 69 66 |stlife2@.westlif|
00000100 65 33 42 b7 bc a4 f7 87 42 1f a9 70 ab f6 a5 83 |e3B.....B..p....|
df.to_parquet("user.parquet", engine="pyarrow", index=False)
00000000 50 41 52 31 15 04 15 4a 15 4c 4c 15 08 15 00 12 |PAR1...J.LL.....|
00000010 00 00 25 40 04 00 00 00 4d 61 72 6b 05 00 00 00 |..%@....Mark....|
00000020 4b 65 76 69 6e 01 09 3c 53 6d 69 74 68 07 00 00 |Kevin..
00000030 00 57 69 6c 6c 69 61 6d 15 00 15 14 15 18 2c 15 |.William......,.|
00000040 08 15 10 15 06 15 06 1c 36 00 28 07 57 69 6c 6c |........6.(.Will|
00000050 69 61 6d 18 05 4b 65 76 69 6e 00 00 00 0a 24 02 |iam..Kevin....$.|
00000060 00 00 00 08 01 02 03 e4 00 26 d2 01 1c 15 0c 19 |.........&......|
00000070 35 00 06 10 19 18 04 6e 61 6d 65 15 02 16 08 16 |5......name.....|
00000080 c4 01 16 ca 01 26 70 26 08 1c 36 00 28 07 57 69 |.....&p&..6.(.Wi|
00000090 6c 6c 69 61 6d 18 05 4b 65 76 69 6e 00 19 2c 15 |lliam..Kevin..,.|
000000a0 04 15 00 15 02 00 15 00 15 10 15 02 00 00 00 15 |................|
000000b0 04 15 48 15 4a 4c 15 08 15 00 12 00 00 24 44 03 |..H.JL.......$D.|
000000c0 00 00 00 55 53 41 06 00 00 00 43 61 6e 61 64 61 |...USA....Canada|
000000d0 02 01 11 34 4b 09 00 00 00 41 75 73 74 72 61 6c |...4K....Austral|
000000e0 69 61 15 00 15 14 15 18 2c 15 08 15 10 15 06 15 |ia......,.......|
000000f0 06 1c 36 00 28 03 55 53 41 18 09 41 75 73 74 72 |..6.(.USA..Austr|
00000100 61 6c 69 61 00 00 00 0a 24 02 00 00 00 08 01 02 |alia....$.......|
00000110 03 e4 00 26 a6 04 1c 15 0c 19 35 00 06 10 19 18 |...&......5.....|
00000120 07 63 6f 75 6e 74 72 79 15 02 16 08 16 c2 01 16 |.country........|
00000130 c8 01 26 c4 03 26 de 02 1c 36 00 28 03 55 53 41 |..&..&...6.(.USA|
00000140 18 09 41 75 73 74 72 61 6c 69 61 00 19 2c 15 04 |..Australia..,..|
'Name': ['Alice', 'Bob', 'Charlie'],
'City': ['New York', 'San Francisco', 'Los Angeles']
table = pa.Table.from_pandas(df)
# Define the Parquet file schema
# Specify the file path for the Parquet file
# Write the Arrow Table to a Parquet file
with pq.ParquetWriter(parquet_file, parquet_schema, version='2.6') as writer:
print(f"Parquet file '{parquet_file}' created successfully.")
parquet_file_path = 'user.parquet'
with pq.ParquetFile(parquet_file_path) as reader:
file_metadata = reader.metadata
format_version = file_metadata.format_version
print(f"format_version : {format_version}")
Header -Metadata offset & Length.
먼저 Row Group 의 구조부터 알아보도록 하겠습니다.
Row Group 의 구조는 아래와 같습니다.
'Name': ['Alice', 'Bob', 'Charlie'],
'City': ['New York', 'San Francisco', 'Los Angeles']
table = pa.Table.from_pandas(df)
# Write the Arrow Table to a Parquet file
with pq.ParquetWriter(parquet_file, parquet_schema) as writer:
writer.write_table(table, row_group_size=1)
print(f"Parquet file '{parquet_file}' created successfully.")
parquet_file_path = 'user.parquet'
file = pa.parquet.ParquetFile(parquet_file_path)
with pq.ParquetFile(parquet_file_path) as reader:
file_metadata = reader.metadata
num_row_groups = reader.num_row_groups
print(f"num_row_groups : {num_row_groups}")
Row Group 을 나눔으로써 얻을 수 있는 이점은
Parquet 데이터를 Row Group 별로 병렬 처리할 수 있습니다.
-> {"name" : "Alice", "age" : 25}
-> {"name" : "Bob", "age" : 30}
-> {"name" : "Carol", "age" : 35}
Row Group 의 사이즈가 1인 경우에는 3개의 Row Group 이 생성됩니다.
-> {"name" : "Alice", "age" : 25}
-> {"name" : "Bob", "age" : 30}
-> {"name" : "Carol", "age" : 35}
table = pa.Table.from_pydict({
"name": ["Alice", "Bob", "Carol"],
# Write the table to a Parquet file
pa.parquet.write_table(table, "parquet_file.parquet", page_size=100000, compression="snappy")
만약, Row Group 의 사이즈가 3, Page 의 사이즈가 1인 경우,
아래와 같은 구성을 이룹니다.
-> {"name" : "Alice", "age" : 25}
-> {"name" : "Bob", "age" : 30}
-> {"name" : "Carol", "age" : 35}
BigData/Parquet2023. 12. 8. 05:37
- 목차
Parquet Reader 로 Parquet 메타데이터 읽기.
Parquet Reader 로 Parquet Row Group 읽기.
함께 보면 좋은 글.
https://westlife0615.tistory.com/50
- 목차 관련된 글 https://westlife0615.tistory.com/333 Avro Serialization 알아보기. - 목차 관련된 글 https://westlife0615.tistory.com/332 Avro File 알아보기 - 목차 소개. Avro 는 두가지 기능을 제공합니다. 첫번째는 직
소개.
Parquet Reader 들이 어떠한 방식으로 Parquet 파일을 읽어들이는지 자세히 살펴보려고 합니다.
Apache Arrow 기반의 라이브러리들은 많은 부분이 추상화되어 있어, Parquet 파일을 읽어들이는 방식이 명료하게 나타나지 않으며,
Python 관련 라이브러리들 또한 추상화된 부분이 많았습니다.
그래서 java 의 org.apache.parquet parquet-hadoop 라이브러리를 사용할 예정입니다.
https://mvnrepository.com/artifact/org.apache.parquet/parquet-hadoop
Column 기반의 Parquet 파일이 어떠한 방식으로 저장되고 로드되는지 살펴보겠습니다.
Parquet File 생성.
먼저 테스트를 위한 Parquet File 을 생성합니다.
간단하게 생성하기 위해서 python 스크립트를 활용하겠습니다.
먼저 pyarrow 모듈을 설치합니다.
pip install pyarrowCopy
그리고 터미널을 열어 python3 인터프린터 내부로 진입합니다.
python3Copy
그리고 Parquet 파일을 생성합니다.
저는 /tmp/ 디렉토리 내부에 생성하였습니다.
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Create a Pandas DataFrame
data = {'name': [], 'city': []}
for i in range(0, 100000):
data["name"].append("name" + str(i))
data["city"].append("city" + str(i))
df = pd.DataFrame(data)
# Convert Pandas DataFrame to PyArrow Table
table = pa.Table.from_pandas(df)
# Specify the Parquet file path
parquet_file_path ='/tmp/user.parquet'
# Write the PyArrow Table to a Parquet file
pq.write_table(table, parquet_file_path, row_group_size=1000)
print(f'Parquet file written to: {parquet_file_path}')Copy
위 스크립트로 생성되는 user.parquet 파일은
name 과 city 칼럼을 가집니다.
그리고 row_group_size 를 1000 으로 두어서, 100 개의 RowGroup 이 생성되도록 조작하였습니다.
생성된 Parquet 파일 구조는 아래와 같습니다.
100 개의 RowGroup 이 있구요.
각 RowGroup 내부에 Column 별로 데이터들이 존재하게 됩니다.
하나의 Column 내부에 저장되는 데이터들의 단위는 Page 라고하며,
RowGroup -> Column -> Page 로 이어지는 구성을 어떻게 읽어들이는지 알아보려고 합니다.

Parquet Reader 로 Parquet 메타데이터 읽기.
저는 java 11 버전에서 테스트를 진행하고 있구요.
아래 모듈의 Parquet Reader 를 사용합니다.
// https://mvnrepository.com/artifact/org.apache.parquet/parquet-hadoop
implementation group: 'org.apache.parquet', name: 'parquet-hadoop', version: '1.13.1'Copy
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.hadoop.ParquetFileReader;
import org.apache.parquet.hadoop.metadata.BlockMetaData;
import org.apache.parquet.hadoop.metadata.ParquetMetadata;
import org.apache.parquet.schema.MessageType;
import java.io.IOException;
public class ParquetTest{
public static void main(String[] args)throws IOException {
Path path =new Path("/tmp/user.parquet");
ParquetFileReader parquetFileReader = ParquetFileReader.open(new Configuration(), path);
ParquetMetadata parquetMetadata = parquetFileReader.getFooter();
MessageType schema = parquetMetadata.getFileMetaData().getSchema();
for (int i =0; i < parquetMetadata.getBlocks().size(); i++) {
BlockMetaData metaData = parquetMetadata.getBlocks().get(i);
System.out.println("RowCount " + i + ": " + metaData.getRowCount());
System.out.println("RowIndexOffset " + i + ": " + metaData.getRowIndexOffset());
System.out.println("schema " + i + ": " + schema.toString());
}
parquetFileReader.close();
}
}ColumnDescriptor columnDescriptor = schema.getColumns().get(columnIndex);
PageReader pageReader = pageReadStore.getPageReader(columnDescriptor);
ColumnReader colReader = colReadStore.getColumnReader(columnDescriptor);
long valueSize = pageReader.getTotalValueCount();
for (int i =0; i < valueSize; i++) {
String value = colReader.getBinary().toStringUsingUTF8();
System.out.println(value);
colReader.consume();
}
}
}
parquetFileReader.close();
}
}
아래 결과는 생략된 버전이긴하지만,
각 Column 은 row_group_size 만큼씩 읽어들입니다.
name0
name1
name2
name3
name4
name5
name6
name7
name8
name9
city0
city1
city2
city3
city4
city5
city6
city7Copy
[Parquet] Dictionary Encoding 알아보기
BigData/Parquet2024. 3. 24. 10:26
- 목차
들어가며.
이번 글에서는 Parquet 의 Dictionary Encoding 에 대해서 알아보려고 합니다.
Dictionary Encoding 은 큰 길이의 String 을 Number 와 같은 숫자로 표현할 수 있는 방식입니다.
예를 들어, "Python", "Java" "Golang" 과 같인 3개의 텍스트를 Unicode 로써 표현하게 되면
문자의 길이만큼 4byte * length 의 용량을 차지하게 되겠죠 ?
하지만 이를 나열 순서에 따라 0, 1, 2 로 표현하게 되면 데이터의 압축이 가능해집니다.
이러한 방식으로 문자열을 bit 레벨로 압축시켜 표현하는 방식을 Dictionary Encoding 이라고 부릅니다.
Encoding ?
인코딩이란 원본 데이터를 변형하는 것을 의미합니다.
다만 단순한 변형이 아니라"효율적으로 데이터를 저장하기 위해서"또는"안전하게 데이터를 관리하기 위해서"인코딩이라는 데이터 변형을 적용합니다.
즉, 저장의 효율성과 보안적인 측면에서 인코딩이 사용됩니다.
Parquet 과 같은 데이터 파일은 저장의 효율성을 위해서 인코딩을 적용합니다.
즉, 저장되는 파일의 사이즈를 최소화하는데에 초점을 둡니다.
Dictionary Encoding 또한 Parquet 파일에서 사용하는 인코딩 방식 중의 하나입니다.
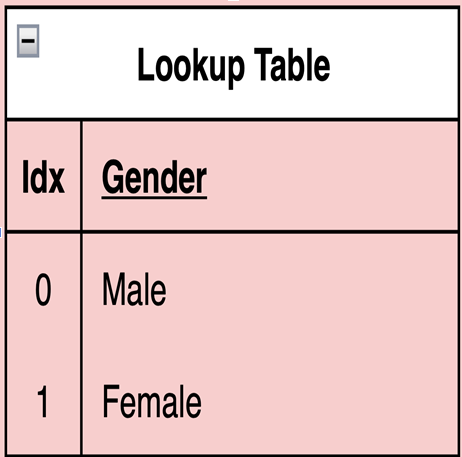
Lookup Table.
Dictionary Encoding 은 내부적으로 Lookup Table 을 생성합니다.
"남"또는"녀"의 값을 가지는성별과 같이Categorical Data를 대상으로 Dictionary Encoding 을 적용할 수 있습니다.
"남" -> 0, "녀" -> 1 과 같이인코딩함으로써 4바이트를 요구하는 Unicode 를 단 1비트로 표현할 수 있게 됩니다.
이로써 1/32 가량의 데이터 압축을 할 수 있죠.
단, 이러한 경우에 Lookup Table 을 생성해여"남" -> 0, "녀" -> 1의 매칭되는 메타데이터를 기록해야합니다.
Cardinality.
Dictionary Encoding 을 적용하기 위해서는 Cardinality 의 개념을 아는 것이 중요합니다.
Cardinality 의 의미는"집합의 크기"라고 합니다.
우리가 수학의 "집합과 원소" 파트에서 배우길 집합은
"어떤 명확한 조건을 만족시키는 서로 다른 대상들의 모임"라고 배웁니다.
이를 데이터의 관점에서 보았을 때, Unique 한 데이터들의 모임이라고 볼 수 있을 것 같습니다.
즉, Cardinality 는 Unique 한 데이터의 갯수를 뜻하구요.
성별과 같은 데이터는 남/녀 라는 두가지 데이터를 가지므로 Low Cardinality.
이름의 성씨과 같이 김/이/최/박/... 등 많은 수의 값을 가지는 경우에는 High Cardinality 라고 볼 수 있습니다.
즉 Categorical Data 를 대상으로 Cardinality 를 적용하곤 합니다.
Cardinality 와 Dictionary Encoding 을 서로 Trade-Off 관계를 갖습니다.
Dictionary Encoding 을 통해서 저장되는 파일의 사이즈가 줄어들긴 합니다.
하지만 High Cardinality 인 데이터는 Lookup Table 의 사이즈가 굉장히 커지는 단점을 가집니다.
그래서 이는 데이터의 중복이 없는 상태이기 때문에 Dictionary Encoding 과 같은 방식으로 인코딩하는 것이 오히려 낭비일 수 있습니다.
Bit Packing.
Bit Packing 이라는 Parquet 의 또 다른 Encoding 방식이 존재합니다.
이름처럼 Bit 단위로 Packing 을 적용합니다.
일반적인 데이터가 바이트 단위로 묶여지는 것과 달리 Bit 단위로 데이터가 관리됩니다.
Bit Packing 은 정보를 Byte 단위가 아닌 Bit 단위로 표현하는 인코딩/압축 방식입니다.
예를 들어, 아래와 같은 4개의 Bool 데이터는 프로그래밍 언어마다 다르지만 최소 1Byte 를 메모리에 차지합니다.
True, False, True, FalseCopy
Bool 자료형이 1 Byte 라고 한다면, 이는 00000001 (b) 또는 00000000 (b) 로 표현되겠죠.
그리고 이 4개의 Bool 타입 데이터가 디스크에 저장되면 4Bytes 를 차지하게 됩니다.
이를 Bit Packing 으로 인코딩하게 되면 4 bit 만으로 저장이 가능합니다.
1010 -> True, False, True, False 로 표현할 수 있기 때문이죠.
또 다른 예시로 1, 2, 3, 4 를 Bit Packing 방식으로 인코딩할 수 있습니다.
이들의 Binary 표현은 00000001, 00000010, 00000011, 00000100 와 같죠.
이를 3자리로 표현하면 1, 10, 11, 100 입니다.
표현상 가장 큰 자리수를 가지는 4가 3자리를 가지므로 이를 기준으로 Bit Packing 을 수행합니다.
그래서 001010011100 -> 001, 010, 011, 100 으로 표현이 가능하죠.
이 또한 Parquet 에서 활용하는 인코딩 방식 중 하나입니다.
Dictionary Encoding 실습.
마지막으로 Dictionary Encoding 으로 인해서 파일이 압축되는 결과를 확인해보겠습니다.
2개의 Parquet 파일을 생성하구요.
각각 1천만개의 텍스트를 생성합니다.
첫번째 파일은"Andy"라는 텍스트를 1천만건 생성을 하구요. 이는 Dictionary Encoding 으로 큰 효율을 볼 수 있습니다.
두번째 파일은"And0" ~ "And9"까지의 데이터를 생성합니다.
총 10개의 Cardinality 를 가지게 됩니다.
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StructType, StringType, StructField
spark = SparkSession.builder.appName("parquet-dictionary-encoding").master("local[*]").config("spark.driver.bindAddress", "localhost").getOrCreate()
rows1 = [Row(name="Andy") for _ in range(10000000)]
schema = StructType([StructField("name", StringType(), False)])
df1 = spark.createDataFrame(rows1, schema)
df1.coalesce(1).write.mode("overwrite").parquet("/tmp/parquet1")
rows2 = [Row(name=f"And{i % 10}") for i in range(10000000)]
df2 = spark.createDataFrame(rows2, schema)
df2.coalesce(1).write.mode("overwrite").parquet("/tmp/parquet2")
spark.stop()Copy
아래의 출력 결과는 생성된 2개의 파일의 위치와 크기를 나타냅니다.
1번째 파일은 27K, 2번째 파일은 272K 의 크기를 가집니다.
즉, Low Cardinality 를 가질수록 큰 압축률을 가지게 됩니다.
[ 128] .
├── [ 192] parquet1
│ ├── [ 0] _SUCCESS
│ └── [ 27K] part-00000-a20e1c94-5607-4dbf-b457-09d2e9ec2468-c000.snappy.parquet
└── [ 192] parquet2
├── [ 0] _SUCCESS
└── [272K] part-00000-9bbfb13d-51eb-43d0-9223-61e0b768b196-c000.snappy.parquetCopy
'컴퓨터 활용(한글, 오피스 등) > 기타' 카테고리의 다른 글
| [데이터베이스 모델링] exERD 설치 (0) | 2025.08.22 |
|---|---|
| [Apache Arrow] Pyarrow Table 알아보기 (0) | 2025.08.22 |
| 공공 폐쇄망 환경에 k8s 기반 AI 플랫폼 구현하기 (0) | 2025.08.21 |
| DB 설계 백서 (0) | 2025.08.20 |
| dbeaver erd diagram 생성 방법 (0) | 2025.08.20 |