BigData/Parquet2024. 3. 8. 22:42
- 목차
이번 글에서는 Pyarrow 의 Table 에 대해서 알아보려고 합니다.
python 3.10 버전과 pyarrow 16.0.0 버전을 사용합니다.
Kaggle 에서 제공되는 Movie Industry 데이터셋을 사용하구요.
영화와 관련된 메타데이터들이 csv 파일 형식으로 제공됩니다.
https://www.kaggle.com/datasets/danielgrijalvas/movies?select=movies.csv
kaggle 사이트로부터 내려받은 csv 파일은 /tmp/movie.csv 위치로 이동시킵니다.
먼저 movie.csv 파일로부터 Pyarrow Table 을 생성합니다.
csv 모듈로부터 pyarrow.lib.Table 객체를 생성할 수 있습니다.
movie_file = "/tmp/movies.csv"
table = csv.read_csv(movie_file)
pyarrow 의 Table.select 함수를 통해서 특정 칼럼만을 조회할 수 있습니다.
이는 SQL 의 Select Query 와 유사합니다.
그리고 select 함수에 의해서 새롭게 생성된 Table 은 to_pylist 함수를 통해서 Python List 객체로 변환할 수 있습니다.
movie_file = "/tmp/movies.csv"
table = csv.read_csv(movie_file)
name_genre_table = table.select(["name", "genre"])
print(name_genre_table.to_pylist())Copy
{'name': 'The Shining', 'genre': 'Drama'},
{'name': 'The Blue Lagoon', 'genre': 'Adventure'},
{'name': 'Star Wars: Episode V - The Empire Strikes Back', 'genre': 'Action'},
{'name': 'Airplane!', 'genre': 'Comedy'}
select 와 to_pylist 함수를 통해서 특정 칼럼의 레코드들을 Python List 형태로 변형하는 방법을 알아보았습니다.
이제 Filter 구문을 통해서 특정 레코드들만을 조회하는 방법을 알아보도록 하겠습니다.
pyarrow 의 compute 모듈은 Filter 와 같은 연산 기능을 제공합니다.
Table 을 필터링하는 코드 구조를 아래와 같습니다.
pyarrow.compute 의 filter 와 equal 과 같이 조건문 연산을 위한 여러 Statement 들이 제공됩니다.
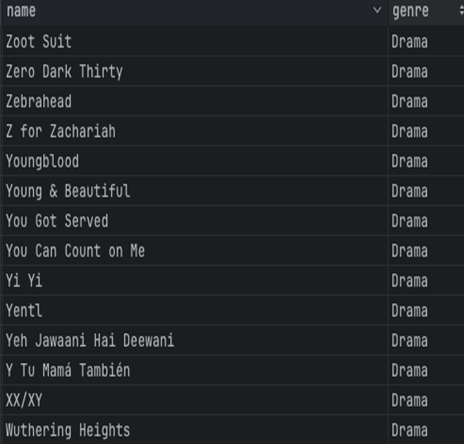
저는 Drama 장르의 Movie 만을 필터링하는 예시를 구현해보았습니다.
drame_movie_table = pc.filter(
pc.equal(name_genre_table["genre"], "Drama")
print(drame_movie_table.to_pylist())Copy
{'name': 'Saving Mbango', 'genre': 'Drama'},
{'name': "It's Just Us", 'genre': 'Drama'}
생성된 Table 을 기반으로 Parquet 파일을 생성하는 방법에 대해서 알아보도록 하겠습니다.
저는 Select 와 Filter 를 기반으로 원하는 형태의 Table 을 만들었습니다.
생성된 Table 은 name 와 genre 칼럼을 가지는 Drama 장르의 Movie 데이터이구요.
이 데이터를 Parquet 파일로 생성해보도록 하겠습니다.
pyarrow.parquet 모듈의 write_table 함수를 사용하면 간단하게 Parquet 파일을 생성할 수 있습니다.
movie_parquet_file = "/tmp/movies.parquet"
pq.write_table(drama_movie_table, movie_parquet_file)Copy
생성된 파일은 아래의 출력 결과와 같이 Parquet 파일로써 저장됩니다.
+--------------------------------+-----+
+--------------------------------+-----+
|Cattle Annie and Little Britches|Drama|
+--------------------------------+-----+Copy
'컴퓨터 활용(한글, 오피스 등) > 기타' 카테고리의 다른 글
| 이클립스에서 ERD를 작성할 수 있는 플러그인 ERMaster 설치하기 (0) | 2025.08.22 |
|---|---|
| [데이터베이스 모델링] exERD 설치 (0) | 2025.08.22 |
| Parquet 알아보기 (0) | 2025.08.22 |
| 공공 폐쇄망 환경에 k8s 기반 AI 플랫폼 구현하기 (0) | 2025.08.21 |
| DB 설계 백서 (0) | 2025.08.20 |